(3) Data Cleansing of Ingested Data
The last article was about ingesting the Johns Hopkins University Datasets into an NoSQL database. This article will focus on the Data preparation stage.
Finding out the details of existent columns
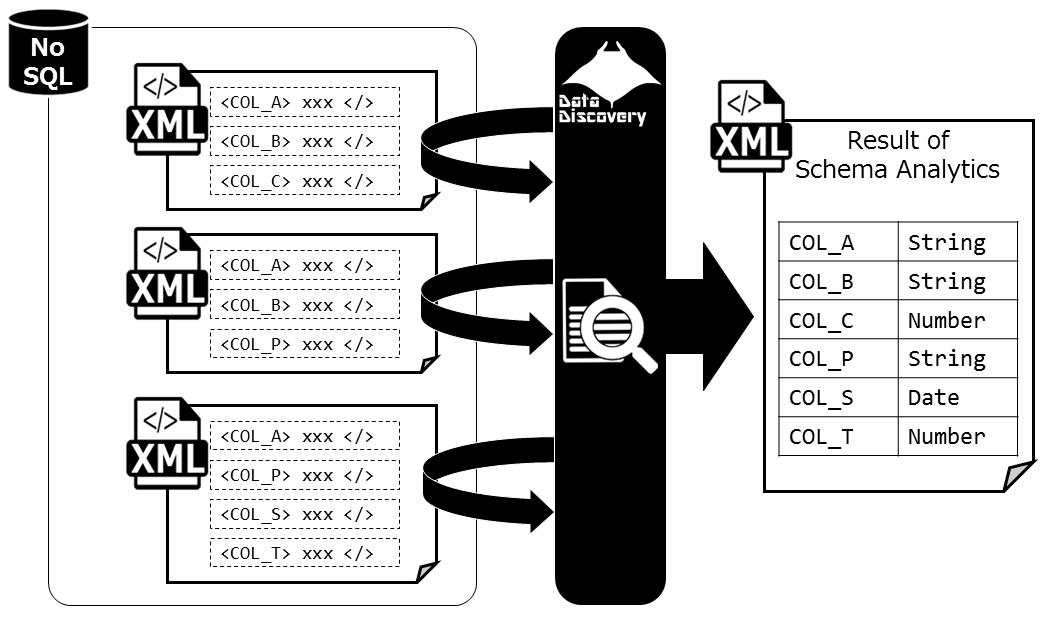
As mentioned on the last article, The Johns Hopkins Datasets changes both the number of columns, and the column name over time. What types of columns will remain after removing redundant columns of each data? The Data Discovery Solution provides functions to explore data inside the NoSQL database, and reverse engineer the schema information of contained data.
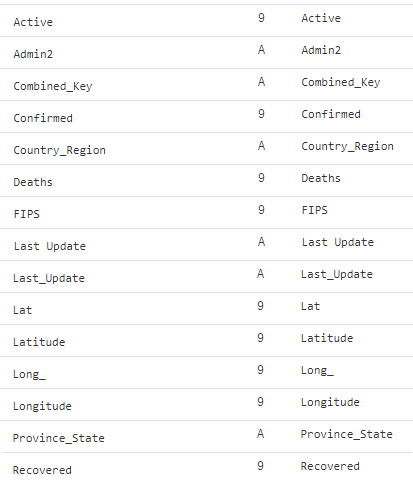
When loading the JHU data, Data Discovery also analyzes the data and figures out the schema information as listed below. The column name is listed in lexical order, the "9" stands for numeric data, and the "A" stands for character data types.
It is written in the last article, "Comparing the Jan 22 data which has 6 columns to March 22 data which has 12 columns, there are differences in the number of columns" but this time, there were additional columns added and now we are dealing with 12 to 15 columns.
The changes made to the JHU datasets are organized below.
- Started with 6 columns, January 22, 2020
- Columns
Latetude and Longitude added March 1, 2020.
- In March 22, Multiple Columns
Active, FIPS, Admin2, Conbined_key were added, and some columns were edited: Last Update was changed to Last_Update, Latitude to Lat, Longitude to Long_.
The facts above means that comparing the first datasets provided in January with the recent datasets will not provide the information needed to understand all the columns. It is a lot of work but, in this case we must check every part of the data, and the efficient way would be to use tools (in this case the Data Discovery) to help out ease the process when looking through every data within.
Cleansing 1: Standardizing the Column names
First, columns that were edited(Last Update to Last_Update, Latitude to Lat, Longitude to Long_.) must be updated in the database.
The March 1st data on the database will be as follows.
Change this to fit the shape of March 22nd's JSON property data(check to see Last Update changed to Last_Update, Latitude to Lat and, Longitude to Long_ ).
The NoSQL that we are using, MarkLogic, can execute JavaScript on DBMS and update the data within the database. Below is the process used to standardize the column names.
Summary: The「Store, then process」method of Schema-less DB
When using the traditional approach with the relational database, the process below would be needed
- Explore every CSV file header and columns from January 22nd to the most recent data
- Define the table(CREATE TABLE) while thinking about the changes, updates that might occur to the columns
- Developing the means for an ETL while thinking about the changes, updates that might occur to the columns
- Ingest CSV files to the database
Compared to the above, when using NoSQL databases, the process changes. The Ingestion comes first, and after the CSV files are stored, then comes the analyzing of schema, then the data processing.
- First Store all the CSV files from January 22nd to the most recent data
- Within the database, explore the JSON property data (using Data Discovery)
- only process the changed columns of data
- New columns are automatically added to the data
As stated, the flexibility of Schema-less databases are demonstrated.
Next, we will go further into the Data Cleansing process.