
MarkLogic Column大量データの一括ロード
はじめに
本稿では、MarkLogicに大量のデータロードをする方法と、実際にロードする例をご紹介します。
大量のデータをロードする方法
MarkLogicに大量のデータロードをする方法としてよく使われる、オープンソース のMLCP(MarkLogic Content Pump)について紹介します。
MLCPとは
Javaベースのコマンドラインツールであり、MarkLogicに対するデータのインポート・エクスポートを行う機能を備えています。各機能では、複数スレッドによる並列処理が可能です。
読み取り可能なフォーマットとしては、以下に対応しています。
- XML、JSON、triple、text、CSV、binary、ZIP、GZIP、archive
MLCP実行時、主に使用するオプションを示します。
| オプション | 説明 |
|---|---|
| host | MarkLogicホスト名か、IPアドレスを設定する。 |
| username | 実行ユーザを設定する。 |
| password | 実行ユーザのパスワードを設定する。 |
| port | MarkLogicのXDBCサーバのポート番号を設定する。 |
| thread_count | 並列実行するスレッド数を設定する。デフォルトは4。 |
| batch_size | 1 回のリクエストで処理するファイルの数を記載する。 デフォルトは100で、最大は200。 |
| delimiter | CSVなど、区切り文字のあるデータの場合に設定する。 デフォルトはカンマ(,)。 |
| document_type | ロード後のデータの形式を明示的に指定する場合に使用する。設定値は(mixed, xml, json, text, binary)のいずれか。 |
| input_file_path | ロードするデータのファイルシステムのパスを指定する。 |
| input_file_type | ロードするデータのファイルタイプを明示的に指定する場合に使用する。設定値は(documents, delimited_text, delimited_json, forest, rdf, archiveなど)。デフォルトはdocuments。 |
| input_compressed | ロードデータが、圧縮ファイルの場合にtrueを指定する。 デフォルトは false。 |
| mode | ファイルの取り込みのモードを指定する。localのみ指定可能。 |
| options_file | オプションを記載したファイルを使用する場合に指定する。ファイルのパスを指定する。 |
| output_uri_prefix | ロード後のパスの先頭に追加する場合に指定する。 |
| output_uri_replace | ロード前後のパスを置換する場合に指定する。 |
| output_uri_suffix | ロード後のパスの最後に追加する場合に指定する。 |
| generate_uri | trueを指定した場合、JSONやCSVなど1ファイルに複数行あるデータに対して、1行を1ファイルに分割してロードする。分割したファイルのURIは枝番付きとなる。 |
MLCPのインストール方法
MLCPを以下のサイトからダウンロードします。
https://developer.marklogic.com/products/mlcp/
binaryのZIPファイルをダウンロードして、データロードを行う環境で解凍します。

※MLCPを使用するにはJavaが必要ですが、ここではJavaはインストールされていることを前提とします。
これでMLCPのインストールは完了となります。
MLCPを使用したロード
ここでは、MLCPを使用してMarkLogicのDocumentsデータベースにXML・CSV・binaryをロードする方法をそれぞれ紹介します。
性能の観点から、MLCPを実行するサーバとMarkLogicをインストールしているサーバは分けた方がよいですが、ここでは同一サーバ上で実行します。
MLCPはコマンドラインで実行できますが、シェルにした方が入力ミスの防止にもなりますし、後々使いまわしができるので、シェルを作成します。ロード対象フォルダの指定に汎用性を持たせるよう、第一引数で渡せるようにしています。
各シェルの内容については、この後のロードの中で紹介します。

1.XMLのロード
サンプルデータとして、/data/columndata1フォルダにXMLを10,000ファイル用意します。
xmldata1.xml
・・・
xmldata10000.xml
1.1.MLCPのパラメータ設定
以下の条件でロードを行います。
- /data/columndata1のXMLをロード対象とする。
- MarkLogicの/testパスにロードする。
- 並列実行のスレッド数は16で実行する。
XMLの場合は、以下のオプションを使用します。
| オプション | 設定値 | 説明 |
|---|---|---|
| host | localhost | 本件では、同一サーバからロードするのでlocalhostを指定。 |
| port | 8000 | デフォルトの8000ポートを指定。Documentsデータベースに格納する。 |
| username | mlcpuser | MLCPを実行するMarkLogicのユーザ。 |
| password | MarkLogic | |
| input_file_path | /data/columndata1 | MLCPでロードする対象のフォルダを指定。 |
| document_type | xml | MarkLogicに格納した時のファイル形式をxmlとすることを明示的に指定。 |
| output_uri_prefix | /test | MarkLogicの"/test"配下にロードする指定。 |
| thread_count | 16 | 並列実行数を16に設定。 |
1.2.XMLデータロードの実行
実行するシェルの内容は以下になります。
実行コマンド
ロード対象フォルダとして、第一引数に/data/columndata1を指定して実行します。
sh mlcp_XML_Load_8000.sh /data/columndata1
シェルを実行すると、以下のようなMLCPのログがコンソール上に出力されます。ロード時間が遅い場合は、スレッド数(thread_count)の値を増やして確認します。
MLCPログの確認
MLCPの実行ログを確認して、問題ないことを確認します。
- INPUT_RECORDSは、ロード対象の数を表しており、10,000件がロード対象になったことがわかります。
- OUTPUT_RECORDSは、MLCPが処理した件数を表しており、10,000件処理したことがわかります。
- OUTPUT_RECORDS_COMMITTEDは、MarkLogicへのロードが成功した件数を表しており、10,000件のロードが成功したことがわかります。
- OUTPUT_RECORDS_FAILEDは、MarkLogicへのロードが失敗した件数を表しており、0件と出力されているので、ロードを失敗したデータがないことがわかります。
1.3.ロード結果の確認
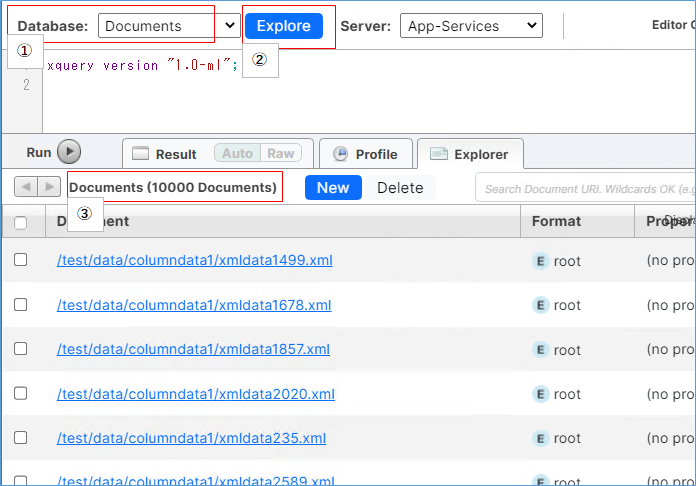
MarkLogicの8000ポートのクエリコンソールにアクセスして、結果を確認します。
①のDatabases項目でDocumentを指定して、②のExploreをクリックすると、③に結果が表示されます。Documentsデータベースに10,000件ロードされたことが確認できます。
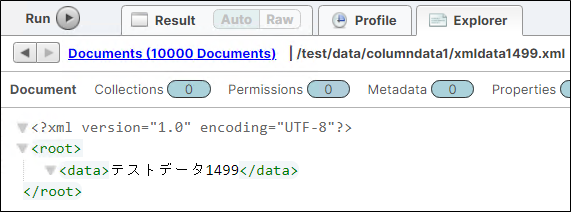
1.4.ロード結果内容の確認
クエリコンソールに表示されるファイルをクリックして、ロードされた内容を確認します。問題ないことを確認できたら、XMLのロードは完了となります。
2.CSVのロード
サンプルデータとして、/data/columndata2フォルダにカンマ区切りのCSV 10レコードを1ファイル用意します。
csvdata10.csv
2.1.MLCPのパラメータ設定
以下の条件でロードを行います。
- /data/columndata2のCSV(カンマ区切り)をロード対象とする。
- MarkLogicの/testcsvパスにロードする。
- MarkLogicに格納する形式はXMLとする。
- CSV1行単位に1個のXMLに分割してMarkLogicに格納する。
- 並列実行のスレッド数はデフォルトで実行する。
CSVの場合は以下のオプションを使用します。
| オプション | 設定値 | 説明 |
|---|---|---|
| host | localhost | 本件では、同一サーバからロードするのでlocalhostを指定。 |
| port | 8000 | デフォルトの8000ポートを指定。Documentsデータベースに格納する。 |
| username | mlcpuser | MLCPを実行するMarkLogicのユーザ。 |
| password | MarkLogic | ユーザのパスワード。 |
| input_file_path | /data/columndata2 | CSVを格納しているフォルダを指定。 |
| input_file_type | delimited_text | ロード対象データが、区切られたテキストであることを指定。 |
| delimiter | "," | ロード対象データの区切り文字がカンマ","であることを指定。 |
| document_type | xml | MarkLogicに格納した時のファイル形式をxmlとすることを明示的に指定。 |
| output_uri_prefix | /testcsv | MarkLogicの"/testcsv"配下にロードする指定。 |
| output_uri_suffix | .xml | -generate_uriで分割した場合、ファイル名の最後(拡張子の後)に枝番が付与されるため、拡張子を別途付与する。 |
| generate_uri | true | データ1行を1ファイルに分割してロードする指定。 |
2.2.CSVデータロードの実行
実行するシェルの内容は以下になります。
実行コマンド
ロード対象フォルダとして、第一引数に/data/columndata2を指定して実行します。
sh mlcp_CSV_Load_8000.sh /data/columndata2
シェルを実行すると、以下のようなMLCPのログがコンソール上に出力されます。
MLCPログの確認
MLCPの実行ログを確認して、問題ないことを確認します。
- INPUT_RECORDSは、ロード対象の数を表しており、10件がロード対象になったことがわかります。
- OUTPUT_RECORDSは、MLCPが処理した件数を表しており、10件処理したことがわかります。
- OUTPUT_RECORDS_COMMITTEDは、MarkLogicへのロードが成功した件数を表しており、10件のロードが成功したことがわかります。
- OUTPUT_RECORDS_FAILEDは、MarkLogicへのロードが失敗した件数を表しており、0件と出力されているので、ロードを失敗したデータがないことがわかります。
2.3.ロード結果の確認
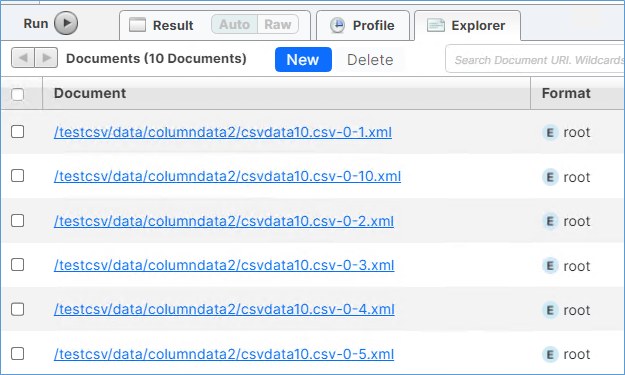
MarkLogicの8000ポートのクエリコンソールにアクセスして、結果を確認します。
Documentsデータベースに10件ロードされたことが確認できます。
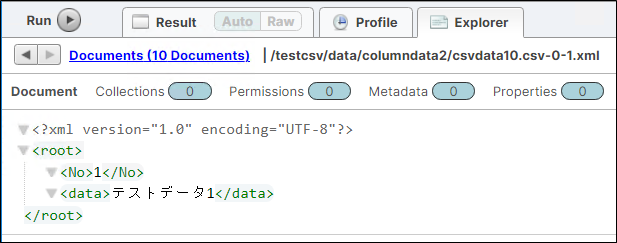
2.4.ロード結果内容の確認
クエリコンソールに表示されるファイルをクリックして、ロードされた内容を確認します。XMLの仕様としてルート要素が必須なので、デフォルトではroot要素が付与されます。子要素にCSVの項目と値が格納されます。問題ないことを確認できたら、CSVのロードは完了となります。
3.binaryのロード
サンプルデータとして、/data/columndata3フォルダにbinaryを5ファイル用意します。
3.1.MLCPのパラメータ設定
以下の条件でロードを行います。
- /data/columndata3のbinary5ファイルをロード対象とする。
- MarkLogicの/testbinaryパスにロードする。
- 並列実行のスレッド数はデフォルトで実行する。
binaryの場合は以下のオプションを使用します。
| オプション | 設定値 | 説明 |
|---|---|---|
| host | localhost | 本件では、同一サーバからロードするのでlocalhostを指定。 |
| port | 8000 | デフォルトの8000ポートを指定。Documentsデータベースに格納する。 |
| username | mlcpuser | MLCPを実行するMarkLogicのユーザ。 |
| password | MarkLogic | ユーザのパスワード。 |
| input_file_path | /data/columndata3 | binaryを格納しているフォルダを指定。 |
| document_type | binary | MarkLogicに格納した時のファイル形式をbinaryとすることを明示的に指定。 |
| output_uri_prefix | /testbinary | MarkLogicの"/testbinary"配下にロードする指定。 |
3.2.binaryデータロードの実行
実行するシェルの内容は以下になります。
実行コマンド
ロード対象フォルダとして、第一引数に/data/columndata3を指定して実行します。
sh mlcp_binary_Load_8000.sh /data/columndata3
シェルを実行すると、以下のようなMLCPのログがコンソール上に出力されます。
MLCPログの確認
MLCPの実行ログを確認して、問題ないことを確認します。
- INPUT_RECORDSは、ロード対象の数を表しており、5件がロード対象になったことがわかります。
- OUTPUT_RECORDSは、MLCPが処理した件数を表しており、5件処理したことがわかります。
- OUTPUT_RECORDS_COMMITTEDは、MarkLogicへのロードが成功した件数を表しており、5件のロードが成功したことがわかります。
- OUTPUT_RECORDS_FAILEDは、MarkLogicへのロードが失敗した件数を表しており、0件と出力されているので、ロードを失敗したデータがないことがわかります。
3.3.ロード結果の確認
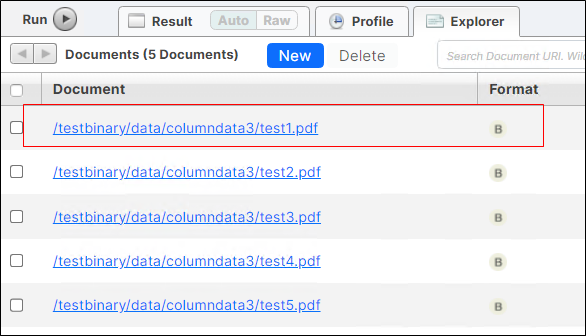
MarkLogicの8000ポートのクエリコンソールにアクセスして、結果を確認します。
Documentsデータベースに5件ロードされたことが確認できます。
クエリコンソールに表示されるファイルをクリックして、ロードされた内容を確認します。問題ないことを確認できたら、binaryのロードは完了となります。
まとめ
本稿の内容をまとめます。
- MarkLogicの大量データロードツールとしてJavaベースのMLCPを紹介しました。
- XML・CSV・binaryを対象にMLCPを用いたインポートの方法を示しました。
今回実施したもの以外にJSONやtripleなどもMLCPでロードすることができます。様々な形式のファイルをロードする場合でも、形式ごとにシェルを作成しておけば、利用しやすくなります。
ロード処理時間が気になったら、MLCPのオプションのthread_countなどを調整してみて下さい。
