(5) NoSQL時代のデータモデル「HyperCube」
前回までは、ジョンズ・ホプキンス大学が開示しているCOVID-19関連データを収集・蓄積し、不揃いなデータのクレンジングを実施しました。今回からは、このデータを元にWebブラウザ上でピボット分析をしたり、折れ線グラフを描画したりできるようにする手順を示します。
HyperCubeというデータモデル
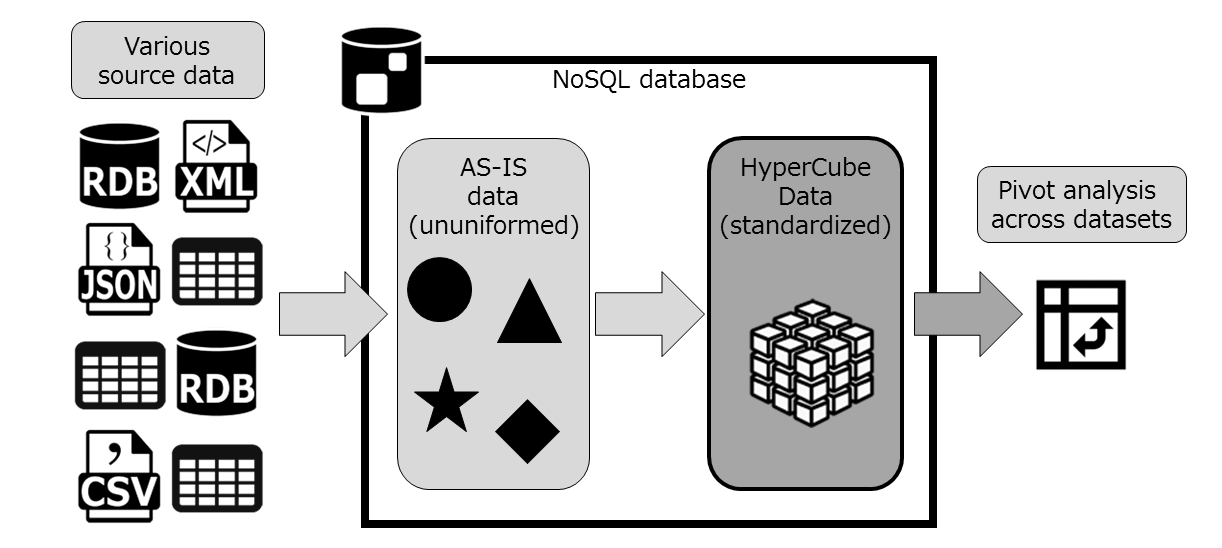
ここで、「HyperCube」についてご説明しなければなりません。HyperCubeは、NTTデータが提唱するNoSQL時代のデータモデルのひとつです。それは、バラツキのあるソースデータをある程度ルールに従って標準化しつつ、NoSQLデータベースの柔軟さを活かして変化に強くする、そんな半剛半柔なデータモデルです。
NoSQLデータベース上で、AS-ISデータを元にHyperCubeを作り出すことで、データセットを横断した分析ができるようになります。
実はこれまで取り込んできた、ジョンズ・ホプキンス大学のCOVID-19関連データ「だけ」を対象に分析するのであれば、わざわざHyperCubeを作る必要はありません。しかしこの連載の中では、これ以外のデータセットも取り込んでデータセット横断での分析をしていくことになります。そのため、HyperCubeにすることが後々効果を発揮してくるはずです。
課題:レイアウトの不揃いと、コード体系の不揃い
それでは、HyperCubeがどういうものか、詳しくご紹介していきます。
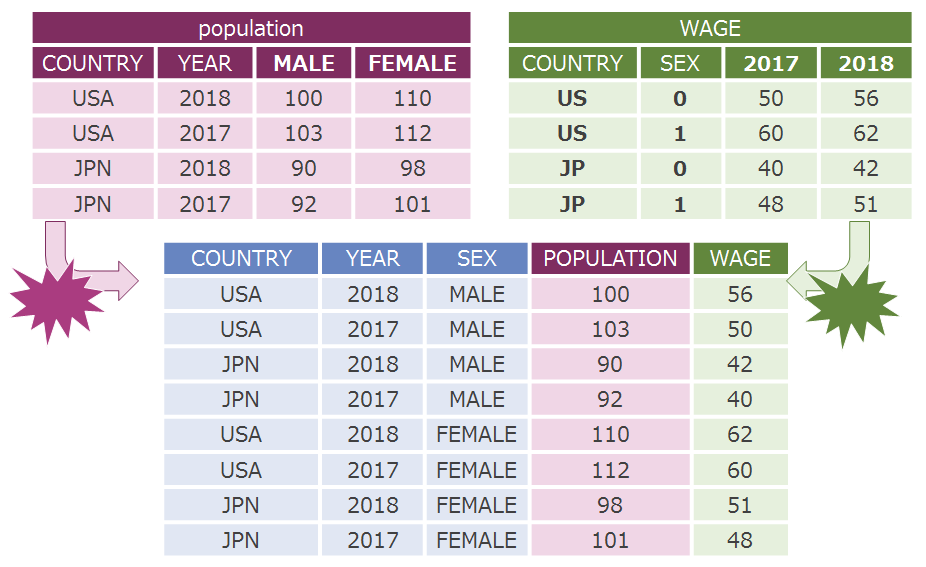
サイロ化されたシステムから収集した様々なデータセットは、「データレイアウト」「コード体系」の2つが不揃いであることが一般的です。
例えば、以下の絵では、紫色の「population」というデータセットと、緑色の「WAGE」というデータセットを横断分析しようとしているところです。紫色の「population」は「性別」が「MALE」「FEMALE」の各カラム自体で表現されており、「年」は「YEAR」というカラムのレコード値で表現されています。逆に緑色の「WAGE」は「性別」が「SEX」というカラムのレコード値で表現され、「年」が「2017」「2018」というカラム自体で表現されています。これが、不揃いなレイアウトの典型的な例です。また、「国」も、紫色の「population」では「USA」「JPN」と3桁のコード、緑色の「WAGE」では「US」「JP」と2桁のコードで表現されています。これが、不揃いなコード体系の典型的な例です。
この2つのデータセットを結合して横断的に分析できるようにするためには、ちょっとしたステップが発生して面倒だな、というのはご理解いただけると思います。
HyperCubeのデータレイアウト
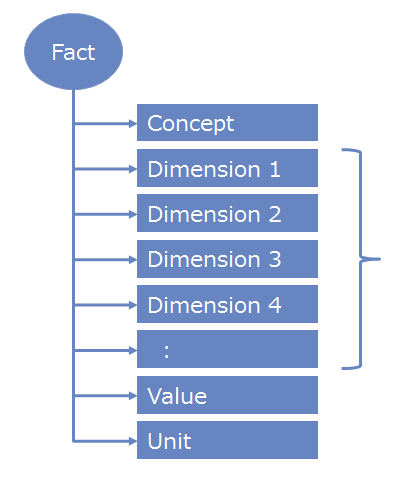
上記の課題のうち「不揃いなレイアウト」について、HyperCubeは「統一的なデータレイアウト」に変換させることで、標準化を図ります。すなわち、あらゆるFactデータについて以下のレイアウトで定義します。
-
- Concept
- Factの「主要素」。1つのFactに必ず1つだけ存在する。
-
- Dimensions
- 様々な「軸」。1つのFactに複数個存在し得る。
-
- Value
- Fact の値。1つのFactに必ず1つだけ存在する。
-
- Unit
- Valueに対する単位(特にValueが数値の場合)。1つのFactに1つまで存在する。
実際には、HyperCubeのFactデータは、以下のようなJSON形式で保持されます。
およそすべてのデータは、このHyperCubeのデータモデルで表現することが可能です。
Concept、Dimension、Valueといった用語が出てきて難しく感じるかもしれませんが、コツがつかめてしまえば非常に簡単です。
ポイントは、日本語の文章にした場合、以下のように切り分けると、たいていうまくいきます。
- 「~の」という部分は様々な「Dimension」
- 「~は」という部分が唯一の「Concept」
- 「~だ」という部分が唯一の「Value」
例えば、「NTTデータの 2019年度の 連結の 売上高は 2兆2668億円だ」という決算短信由来のデータの場合、HyperCubeのFactデータは論理的には以下のように表現できます。
「NTTデータの 2020年6月1日現在の 本社所在地は 東京都江東区だ」という有価証券報告書由来のデータの場合、以下のように表現できます。
HyperCubeのデータモデルの最大の特徴は、標準化と柔軟性の絶妙なバランスです。様々なデータレイアウトをすべからく統一されたレイアウトに標準化する点は、「ありのままを許さない」という意味でやや窮屈に感じる部分かもしれません。しかし、これによって「Conceptが『本社所在地または売上高』かつDim報告企業が『NTTデータ』」という条件での横断的な検索を実行することが可能になるのです。
一方で、「Dimension」の数に制限がなく、追加的に増やしていくことができる、という点は、まさにNoSQLデータベースの柔軟さを発揮させているところだと言えます。上例では「Dim報告企業」「Dim会計年度」「Dim連結単体」「Dim時点」といったDimensionが登場しますが、様々なデータセットをHyperCube化していけばいくほど、どんどんDimensionは増えていきます。その度にテーブル定義をし直したりしなくてよいのが、NoSQLデータベースのよいところです。
これが、冒頭で「半剛半柔なNoSQL時代のデータモデル」と述べた所以です。
HyperCubeのコード値
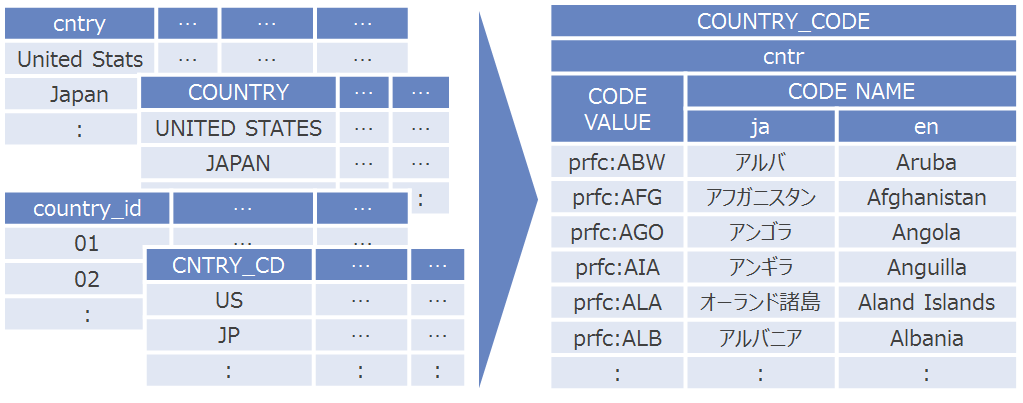
課題の2つ目「不揃いなコード値」について、HyperCubeの世界では可能な限りデータを、一元的に管理されたコード値で定義します。コード値で管理する理由は以下の通りです。
- 「同義」なものを明確に定義する
- コード名称の変更を一元的に管理する
- コード名称の国際化に対応する
例えば、上の「NTTデータの売上高」と「NTTデータの所在地」例では、2つの「NTTデータ」が同じものだ、ということを明確にしなければならない、つまり同じコードを付与しなければならないということです。その際には統一したコード体系を付与することにしますが、その際に証券コードを利用するのか、EDINETコードを利用するのか、法人マイナンバーを利用するのか、または独自の採番をするのか、何かルールを決めます。そして、付与されたコードの値(例えば、証券コードの9613)に対して、対応する統一的なラベルを付与します。マスタで一元管理することで、「株式会社エヌ・ティ・ティ・データ」と「NTTデータ」といった揺らぎを抑止します。日本語、英語、中国語といった各国語表記を定義しておけば、システムの国際化にも対応することもできるでしょう。
まとめ:HyperCubeは半剛半柔なデータモデル
今回は、HyperCubeとは何か、というご説明をしました。どうしてもバラツキのあるデータレイアウトをある程度規律をもった形に標準化する一方で、NoSQLデータベースの柔軟性のメリットも享受する、そんなデータモデルであるという点をご紹介しました。
次回は、実際にジョンズ・ホプキンス大学のCOVID-19データを元に、HyperCubeデータを作っていきます。