(8) NoSQL時代のデータモデル「HyperCube」
前回までは、「ジョンズ・ホプキンス大学が開示しているCOVID-19関連データ」に「Google コミュニティ モビリティ レポート」を組み合わせてHyperCube化し、2つのデータをクロスミックスさせたPivot分析ができるようになることを示しました。
連載の第1回で、本連載での「出来上がりイメージ」として2つご紹介しましたが、そのうち1つ目「時系列の動きを見るような分析」は、これまでの連載で実現できました。今回は、2つ目の「2軸の散布図」に取り組んでみたいと思います。
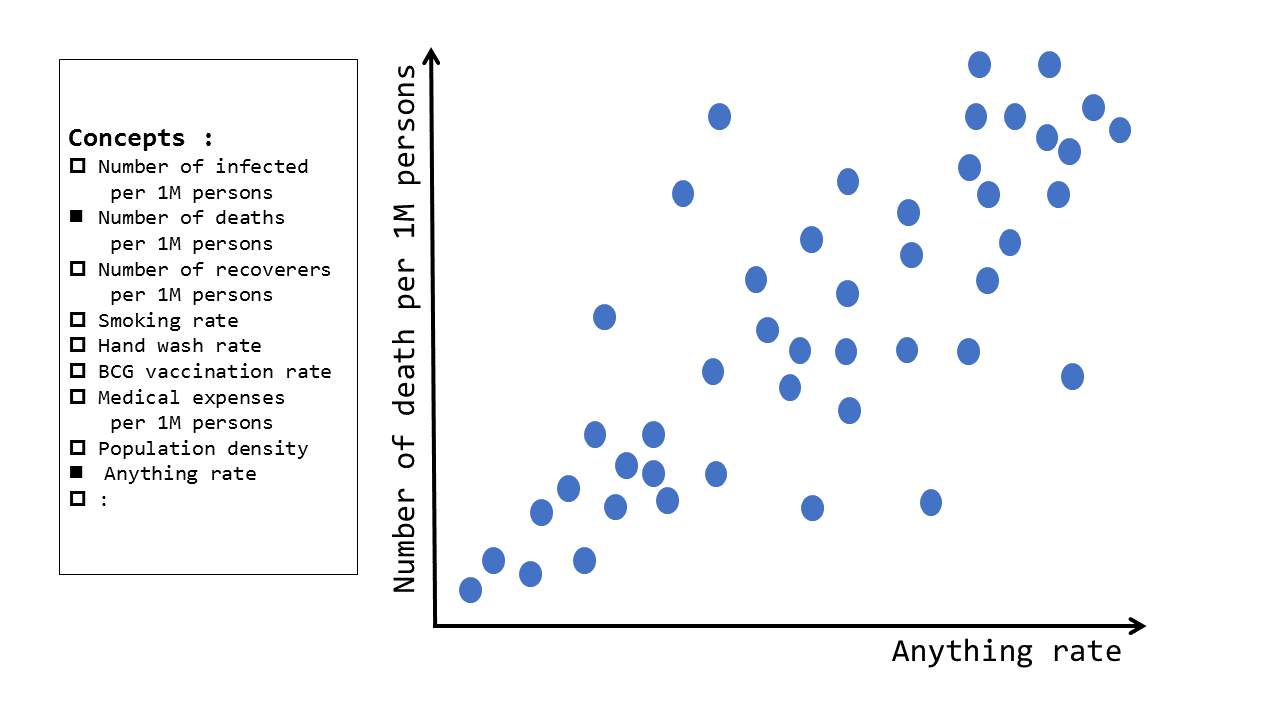
感染・死亡と相関のあるパラメータを探す
いま、世界各国でおよそ同じような感染症対策を実施しているにも関わらず、国ごとの感染者数や死亡者数には大きな違いが出ていて、その理由はそれほど明確ではありません。
- 喫煙者は重症化しやすいようだ
- 糖尿病などの基礎疾患があると重症化しやすいみたいだ
- 手を洗う習慣が根付いている国は感染が広がりにくいのではないか
- BCGワクチンの接種が義務化されている国は感染率が低い気がする
といった様々な説が、信憑性の高いものから低いものまでメディアで挙げられています。
こういう相関関係については、任意の2軸を選択したうえで、散布図の形で確認できるとよいというユースケースです。
今回のデータの形は「国別」
前回のHyperCubeは、「国×地域×日付×主要素」単位でJSONファイルを作ることで、多軸の抽出・分析を可能にしました。特に、時々刻々と変化する感染者数をウォッチするため「日付」の概念が重要でした。
今回の分析は「タバコを吸う人が多いと感染者数が多くなるのではないか」といったようなものであり、「今日の喫煙率」「明日の喫煙率」という日別の推移というよりは、もう少しマクロなトレンド分析になりそうです。「日付」の概念は捨てて、以下のような「国別」のデータを作っていきます。
ソースデータを収集
COVID-19 関連
まずはCOVID-19に関する情報は、前回までと同様にジョンズ・ホプキンス大学が開示しているデータを利用し、国別の感染者数・重傷者数・死亡者数・回復者数を取得します。毎日更新されて開示されているデータですが、今回は任意の時点のデータを取得することにします。
人口統計
また、国別の総人口データも収集します。「100万人あたりの感染者数」という「率」で評価することで、大きな国と小さな国を比較しやすくする目的です。今回は、世界銀行のデータを利用しました。
年齢中央値
高齢者の方が重症化しやすい、という仮説も検証してみたいです。Kaggleのサイトに掲載されている、国別の年齢中央値のデータセットを使ってみることにしました。
喫煙率
喫煙者は重症化しやすい、という仮説も検証してみましょう。WHO (世界保健機関)のデータを元に作られた World Population Review のデータセットを使います。
肥満率
肥満している方は重症化しやすい、という仮説も検証してみます。WHO (世界保健機関)のデータを元に作られた World Population Review のデータセットを使います。
データを統合
ソースデータはCSVで公開されていることが多いのですが、どんどんデータベースに取り込んでいきます。スキーマレスなNoSQL DBは、このような場合にいちいちCREATE TABLEしなくて済むのが本当にラクです。
それぞれのデータセットを、上述のように「国別」に統合していきます。例えば、タイの場合は以下のようなJSONファイルになります。
ソースデータによっては、いくつかの国についての情報が存在しないこともありますが、気にせず「使えるデータだけ使う」というつもりで取り込んでいきます。
画面で確認
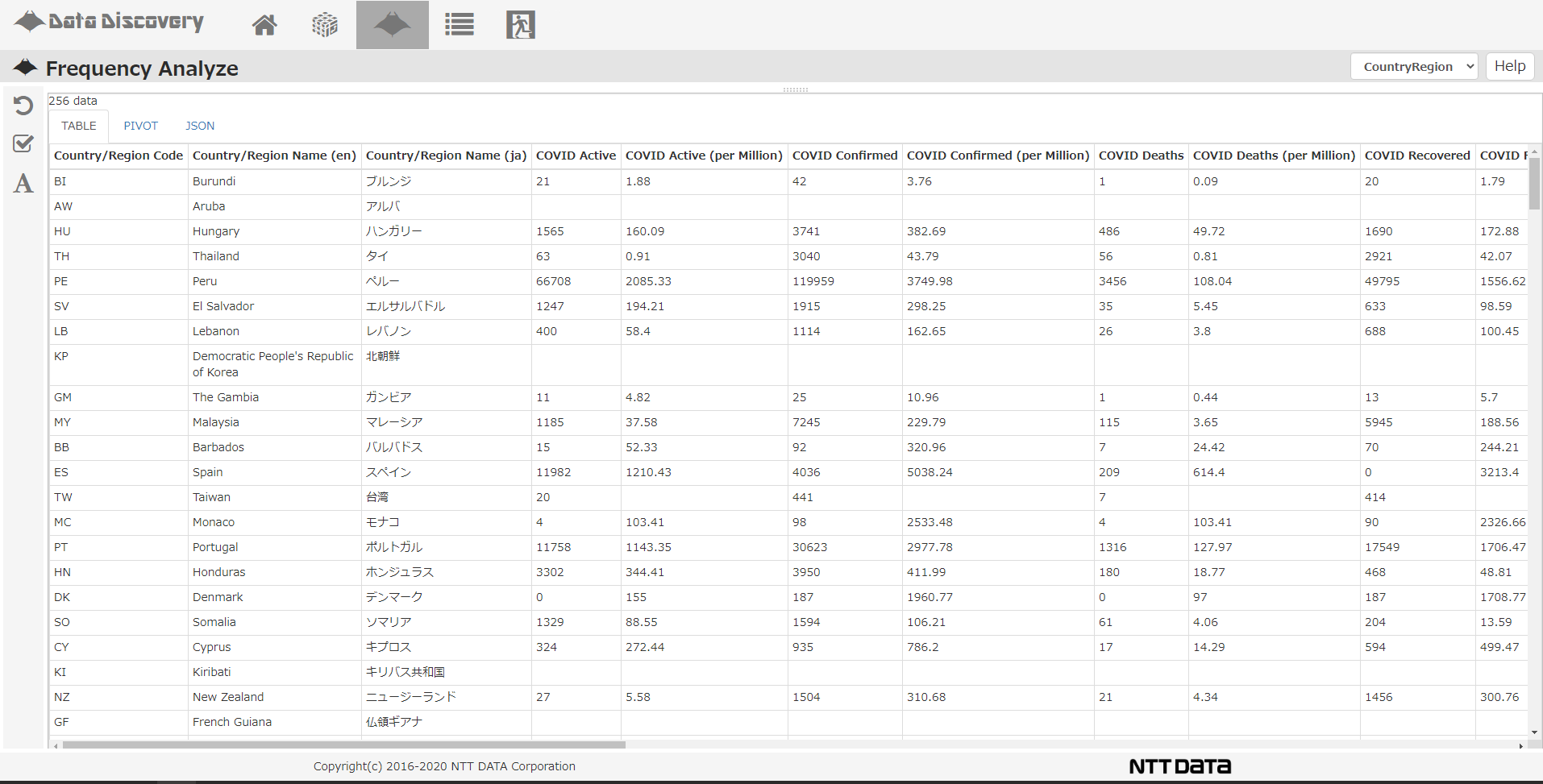
NTTデータのソリューションDataDiscoveryの「Frequency Analyze」画面で、結果を見てみます。
「Table」タブの画面を見ると、256の国・地域が縦に並び、いままで取り込んだ様々な属性値が横に並んでいます。
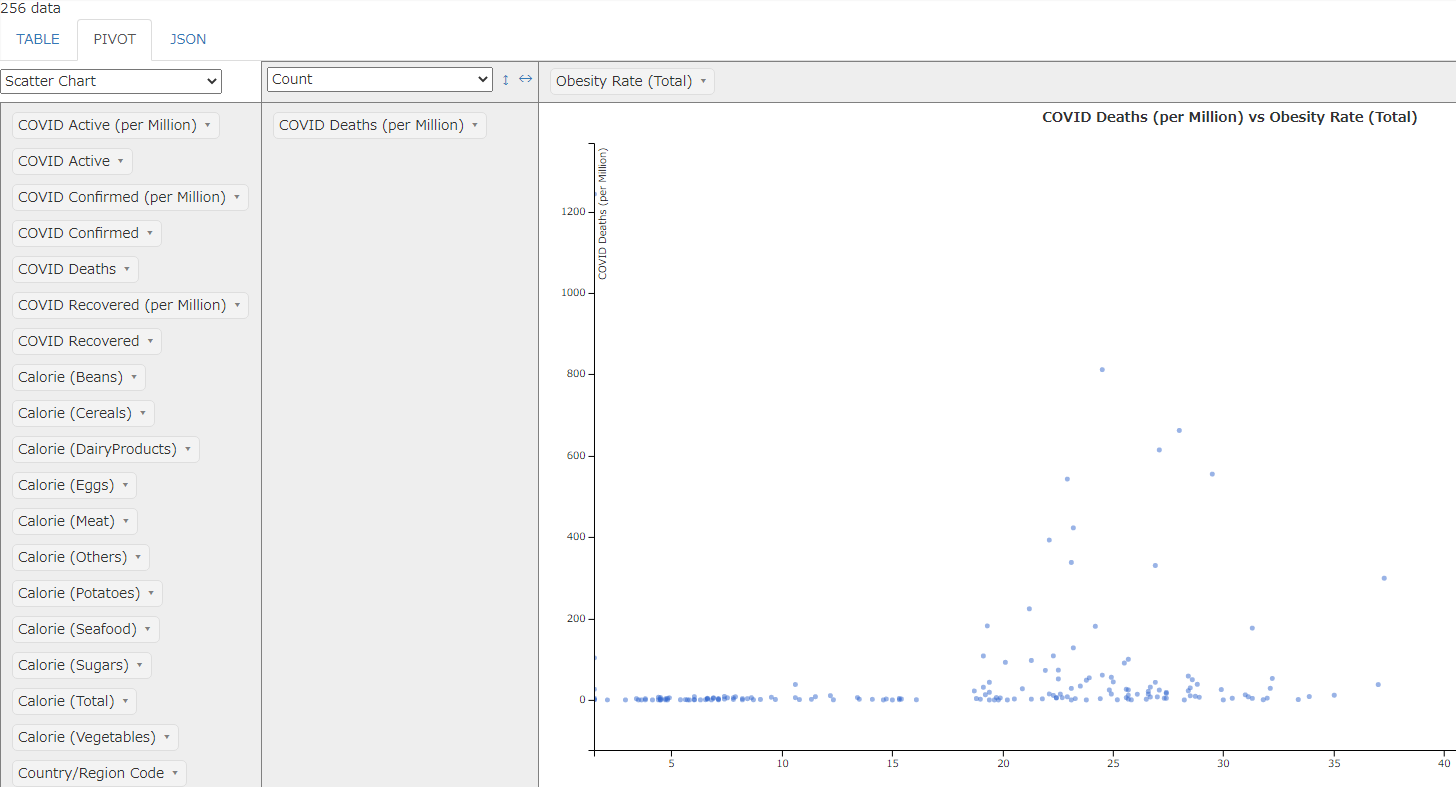
「Pivot」タブを押して、縦軸に「百万人あたりの死亡者数」、横軸に「肥満率」を設定することで、散布図が描画されます。散布図のひとつひとつの青い点が、どこかの国を表現しているというわけです。(あんまり相関がなさそうですね)
連載まとめ:NoSQLでクイックに分析
今回も「由来が様々なデータ」を収集し、それをNoSQLデータベース上で統合して分析をしました。
本連載を通して感じていただきたかったことは、テーブル追加やカラム追加の手間が少ないNoSQL データベースの気軽さです。コラムを見ると、計画的にデータを収集しているように読めるかもしれませんが、実際は仲間とワイワイと「あれも取り込んでみよう、これも突っ込んでみよう」と話しながら臨機応変にやっています。
一方で、スキーマレスとはいえ「どのようなデータモデルで統一するか」という部分は考慮が必要ですし、コード体系は必要に応じて揃える必要があります。バラバラなものをいつまでもバラバラなままにしておいても、分析するときに苦労することになります。
ただし、最初から100点満点の標準化を施す必要はなく、「必要に応じて都度整えていく」というアプローチを採用できるところがNoSQLデータベースの強みといえます。