COVID-19 アドホック分析 (1)
2020年 5月 27日公開
ニルセン 大河 (Taiga Nielsen@NTT DATA)
白水 淳 (Jun Shiromizu@NTT DATA)
本連載ではCOVID-19を題材に、バラエティデータをアドホックに取り込んで分析する「データ統合」の方法論を示します。
(1) COVID-19に関するデータをアドホックに取り込み、活用してみる
仮説検証の「気軽さ」がデータ活用のポイント
デジタル化時代の到来ということで、各企業はDWHの中の伝統的なデータに限らず様々なデータを活用して、新しい価値創造またはコスト削減に取り組んでいます。この「様々なデータ」というのは、例えば今まで活用しきれなかった顧客行動に関するログデータであったり、公開されている社外データだったり、あるいはテキストや画像や音声といった非構造化データであったり、文字通りバラエティに富んだものとなっています。
様々なデータを分析することで、競合他社に先駆けて新しいビジネスアイデアを創出する、または人手に頼っていた業務のうちAIを含めた自動化できる分野を探る。まさにその現場で最重視されているのが「スピード」です。これは、「コンピュータの処理性能」そのものも重要なのですが、より本質的なのが「仮説をすぐに検証できる」という運用のリードタイムです。
例えば、誰かが業務効率化に関する新しいアイデアを思い付いたとします。そのアイデアは、まだ正しいかどうか分からない。本格展開する前に、ファクトデータを使って仮説をざっと検証してみたい。その際に、関係各所にお願いをして回る必要があったり、クレンジングに膨大な手間が掛かったり、または仮説が結局面白くなかった場合に誰かに嫌な顔をされたりするとどうでしょう。億劫で面倒で、せっかくの仮説を検証するための心理的なハードルが非常に高くなります。そして残念ながら、それは実際に多くのデータ活用の現場で起きていることなのです。
さまざまなデータを活用するのにどうしてそんなにリードタイムが取られるのでしょうか。それは、データを活用できる状態まで準備する作業(データ・プレパレーションと呼ばれます)に膨大な時間が掛かるからです。この作業に、アナリストが割く稼働時間は8割とも9割とも言われています。
本連載では、データ活用における仮説検証およびそのための事前準備作業をできるだけ効率よく実施する、そんな方法論を実際の事例に従ってご紹介したいと思います。
「COVID-19」を題材にします
新型コロナウィルス感染症(COVID-19)の世界的な流行で、医療・経済・教育・交通・文化・地域社会に重大な影響を及ぼしています。国別/地域別の感染者数・死亡者数またはPCR検査数・陽性反応数などのデータが多くの組織・機関から開示されています。開示されたデータはメディアによってストレートに報道されるほか、アナリストによって既存のデータと組み合わせた傾向分析が行われています。
今回の連載では、このCOVID-19に関するデータを題材に、様々な由来の異なるデータセットを収集・統合してみて、どのような問題に直面するか。そして、それをどのように効率よく解消するかご紹介してみたいと思います。
今後の連載で次第に明らかになっていきますが、COVID-19に関する分析のために様々なデータを収集することで、私たちは以下のような課題に直面します。
- あるデータセットは、途中で項目(カラム)が増えたり変わったりする
- 日付時刻型の項目の値が、YYYY-MM-DD形式だったり、MM-DD-YY形式だったりと不揃いである
- 英国を表現する値が「UK」だったり「United Kingdom」だったりと不揃いである
このような、増えたり、変わったり、不揃いだったり、よく分からなかったりするデータを効率よく取り扱うために、私たちはNoSQLデータベースを活用し、そのスキーマレスのパワーを活かして効率的に課題を解決していきます。それは、例えば以下のような方法論です。
- CREATE TABLEによる表定義を事前にすることなく、データを格納してすぐに活用する
- 不揃いなデータを、DB格納後に段階的に標準化する
- システム停止することなく、当初存在しなかったデータ項目を追加していく
今回の分析の「出来上がり」をイメージする
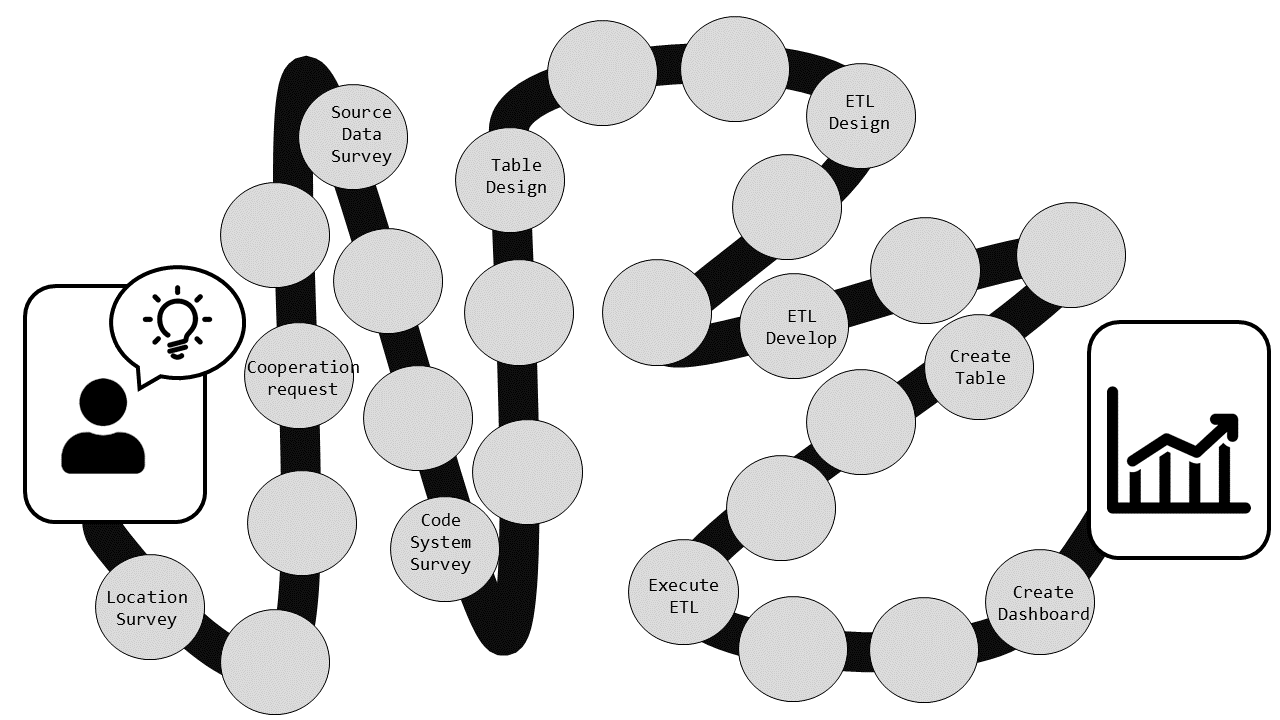
これから「データを集めて、整えて、分析する」という一連の流れをご紹介していくのですが、「どんなゴールに向かってこの作業をしているのか」という点が分からないと、読者の皆さんも辛いと思います。そこで、まずは、今回のデータ統合作業の結果としての分析画面を最初にお示しします。「レシピをお伝えする前に、何の料理を作ろうとしているのか発表する」ということです。
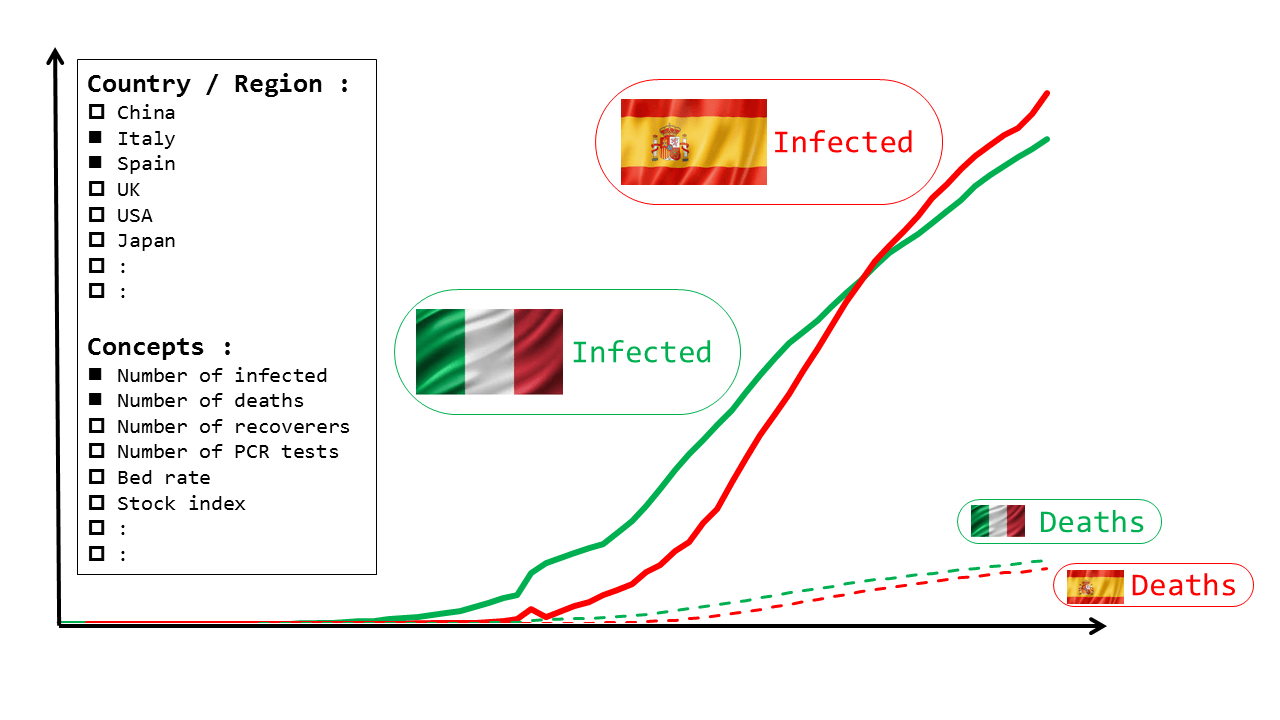
ユースケースのひとつ目は、時系列の動きを見るような分析がしたいです。いくつかの国を選び、いくつかの分析項目を選んで、その推移を確認するものです。例えば、以下の図は、国として{イタリアとスペイン}を、分析項目として{感染者数と死亡者数}を選んだ際のイメージです。
さらにこういうグラフが、ソースデータを超越して、例えば医療関係のデータと経済関係のデータを合わせてプロットしたりできたらよいです。
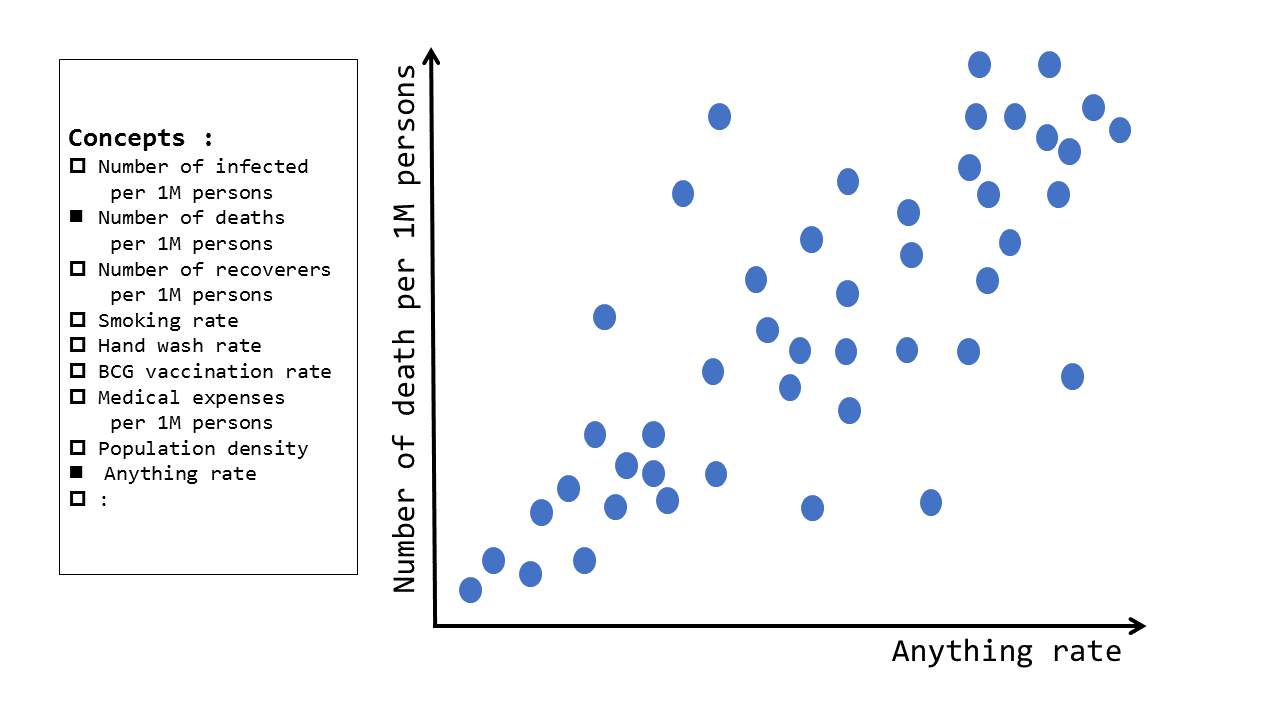
もうひとつのユースケースは、2軸の散布図です。いま、各国でおよそ同じような感染症対策を実施しているにも関わらず、国ごとの感染者数や死亡者数には大きな違いが出ていて、その理由は現在のところ明確ではありません。
- 喫煙者は重症化しやすいようだ
- 糖尿病などの基礎疾患があると重症化しやすいみたいだ
- 手を洗う習慣が根付いている国は感染が広がりにくいのではないか
- BCGワクチンの接種が義務化されている国は感染率が低い気がする
といった様々な説が、信憑性の高いものから低いものまでメディアで挙げられています。
こういう相関関係については、任意の2軸を選択したうえで、以下のような散布図の形で確認できるとよいと考えます。
上記のようなことを実現できるデモシステムを、わたしたちのソリューションでさっと開発しています。
次回から「レシピ」をご紹介
今回は、COVID-19に関する公開データを使って「どんな分析をしたいのか」を示しました。
次回以降、いよいよ「これをどのように実現したか」を詳しくご紹介していきます。まずは、COVID-19関連で最も基本的なデータとなる、ジョンズ・ホプキンス大学が公開する「国別の感染者数・死亡者数・回復者数」のデータを取り込んでいきます。