(2) ジョンズ・ホプキンス大学のデータをデータベースに取り込む
前回は、COVID-19のデータを収集して分析する「出来上がりのイメージ」を示しました。今回から、それを実現する具体的な手段をご紹介していきます。
ジョンズ・ホプキンス大学のデータセットとは
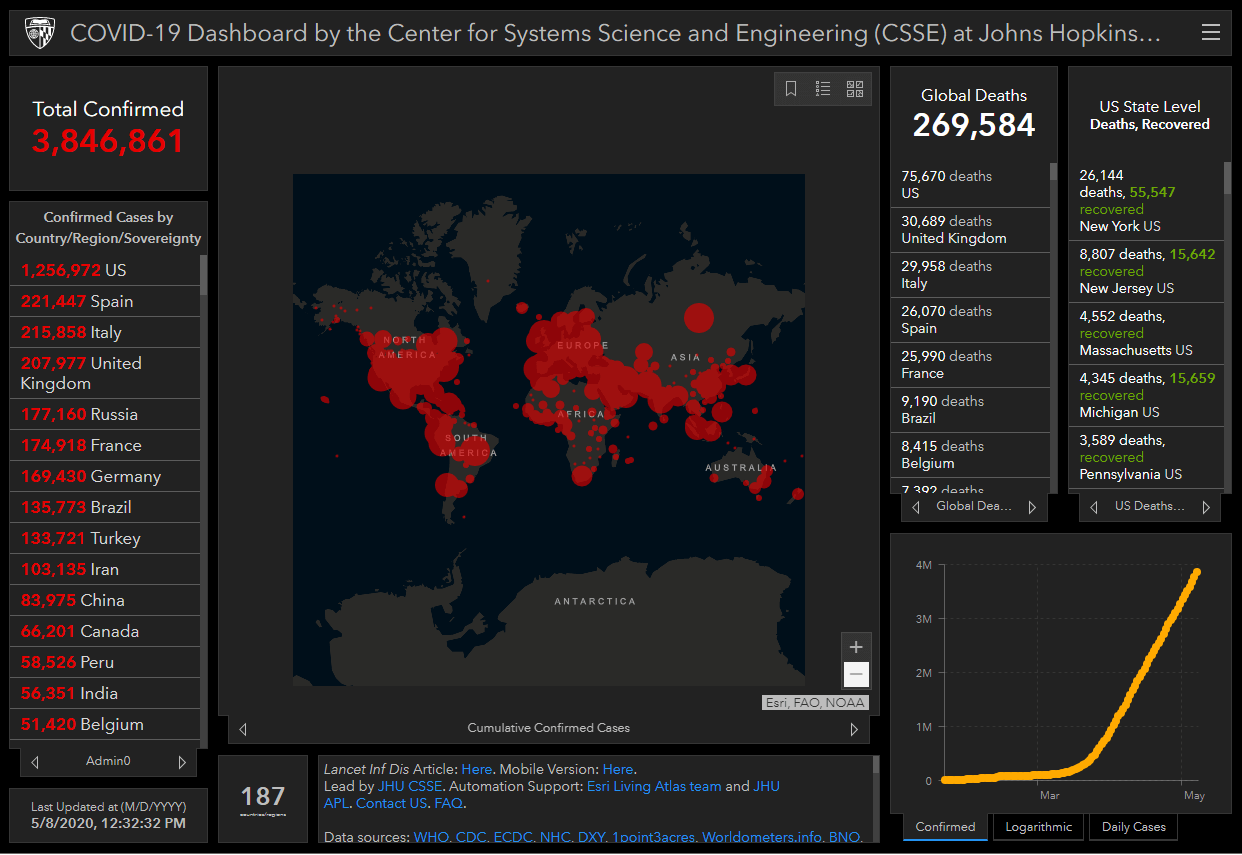
COVID-19の感染者情報を世界中の様々な機関がWebサイトで公開していますが、その中でも特に注目を集めているのがジョンズ・ホプキンス大学の「COVID-19 Dashboard」です。2020年1月にいち早く全世界の感染者情報の開示を開始したこのダッシュボードは、1日10億以上のアクセスを集め、世界中の報道で引用されています。
ジョンズ・ホプキンス大学は、米国メリーランド州の私立大学で、世界屈指の医学部を有する最難関大学のひとつとして知られています。上記ダッシュボードを作成・運用しているのは、同大学のシステム科学工学センター (CSSE)です。
ダッシュボードの感染者データは 世界保健機関(WHO)や各国保険局を中心とした様々な機関から収集したものです。Web スクレイピング技術を用いて自動的に収集され、1 時間ごとにダッシュボードを更新しています。この収集・整理されたデータは、GitHubでも公開されています。
今回はCOVID-19に関する最も基本的な情報として、このGitHubに公開されているデータを活用してみることにしました。
GitHubから感染情報をダウンロードする
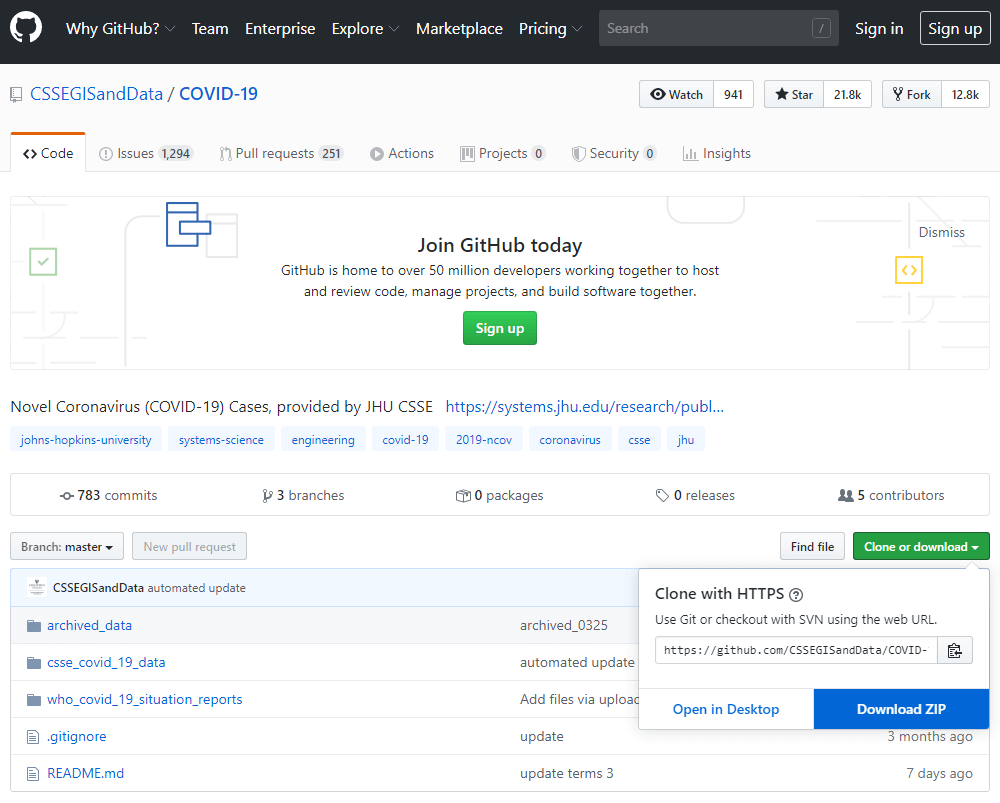
GitHub : COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University
https://github.com/CSSEGISandData/COVID-19
上記のURLにアクセスして、ジョンズ・ホプキンス大学のCOVID-19データのGitHubサイトにアクセスしました。ひととおり「README」に目を通しつつ、善は急げということで早速データをダウンロードしました。
ダウンロードしたデータの中身を確認する
「COVID-19-master.zip」というZIPファイルがダウンロードされますので、これを解凍すると、以下のようなフォルダが展開されました。
大きく3つのフォルダがあり、さらにそれぞれ複数のサブフォルダがあるのですが、この中で私たちはcsse_covid_19_daily_reportsというフォルダに注目しました。
このフォルダの中には「MM-DD-YYYY.csv」というファイル名のCSVファイルが多数格納されています。日次で作られるファイルなのです。
最も古い日付の01-22-2020.csvを開いてみると、以下のようなヘッダ付CSVファイルでした。
これを見やすい表形式に直すとこのようになります。
| Province/State |
Country/Region |
Last Update |
Confirmed |
Deaths |
Recovered |
| Anhui |
Mainland China |
1/22/2020 17:00 |
1 |
|
|
| Beijing |
Mainland China |
1/22/2020 17:00 |
14 |
|
|
| Chongqing |
Mainland China |
1/22/2020 17:00 |
6 |
|
|
| Fujian |
Mainland China |
1/22/2020 17:00 |
1 |
|
|
| Gansu |
Mainland China |
1/22/2020 17:00 |
|
|
|
| : |
: |
: |
: |
: |
: |
カラムが6つ存在します。
- Prooince/State 州とか都道府県の名前(米国や中国など、一部の国のみ)
- Country/Region 国/地域
- Last Update 最終更新日時
- Confirmed 感染が確認された人の数
- Death 死亡した人の数
- Recovered 回復した人の数
つまり、このデータセットを活用すれば、国別の感染者・死亡者・回復者の数を時系列で把握することができるのだと分かりました。
変わる、データレイアウト
他の日付のファイルも開いてみると、このデータセットは途中でレイアウトが変わっているのが分かります。1月22日のデータは上述の通り6カラムでした。2ヶ月後の3月22日には以下の通り12カラムに増えているのです。
また、よく見ると1月22日ではLast Updateだったカラム名が、3月22日にはLast_Updateに変更されていることも分かります(LastとUpdateの間が、ホワイトスペースからアンダースコアに変更されている)。
このように、このデータセットは途中でカラムが増えたり、カラム名が変わったりするのだ、ということが分かりました。
レイアウト不明なデータはNoSQLデータベースへ
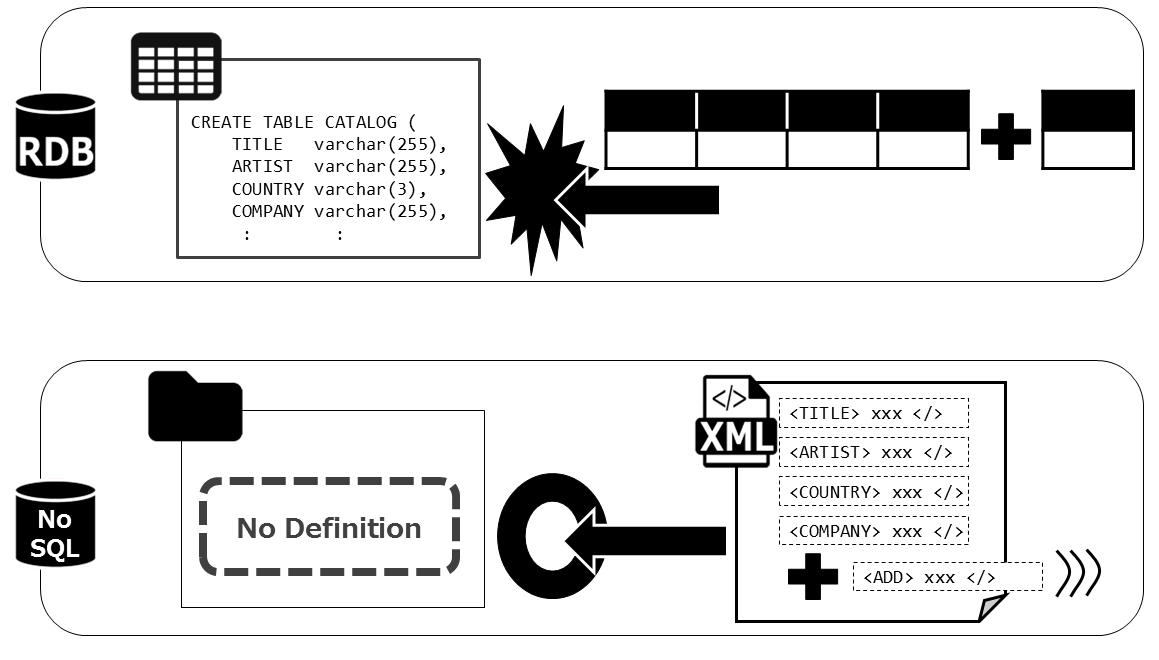
途中でカラムが増えたり、カラム名が変わったりすることは、よくあることです。どんな会社のどんなシステムのデータも、ビジネスの変化に応じてレイアウトを変えていきます。今回のデータは、短期間のうちに全世界に多大な影響をもたらしたCOVID-19がテーマなので、「特に変化が激しい」ものに過ぎないということです。
よって途中でレイアウトが変わるのは仕方のないことなのですが、とはいえどんなカラムが存在するか分からないというのは、そのデータを活用する立場の者にとってはちょっとした課題です。なぜなら、一般的なデータベース、つまりRDBは、データを格納する前にテーブルのレイアウトを定義する必要があるからです。どんなカラムが存在するか分からない、これから変わるかもしれないのであれば、こういうデータは、NoSQLデータベースに格納するのが最適です。スキーマ定義不要でデータを格納しつつ柔軟に検索・活用ができるからです。
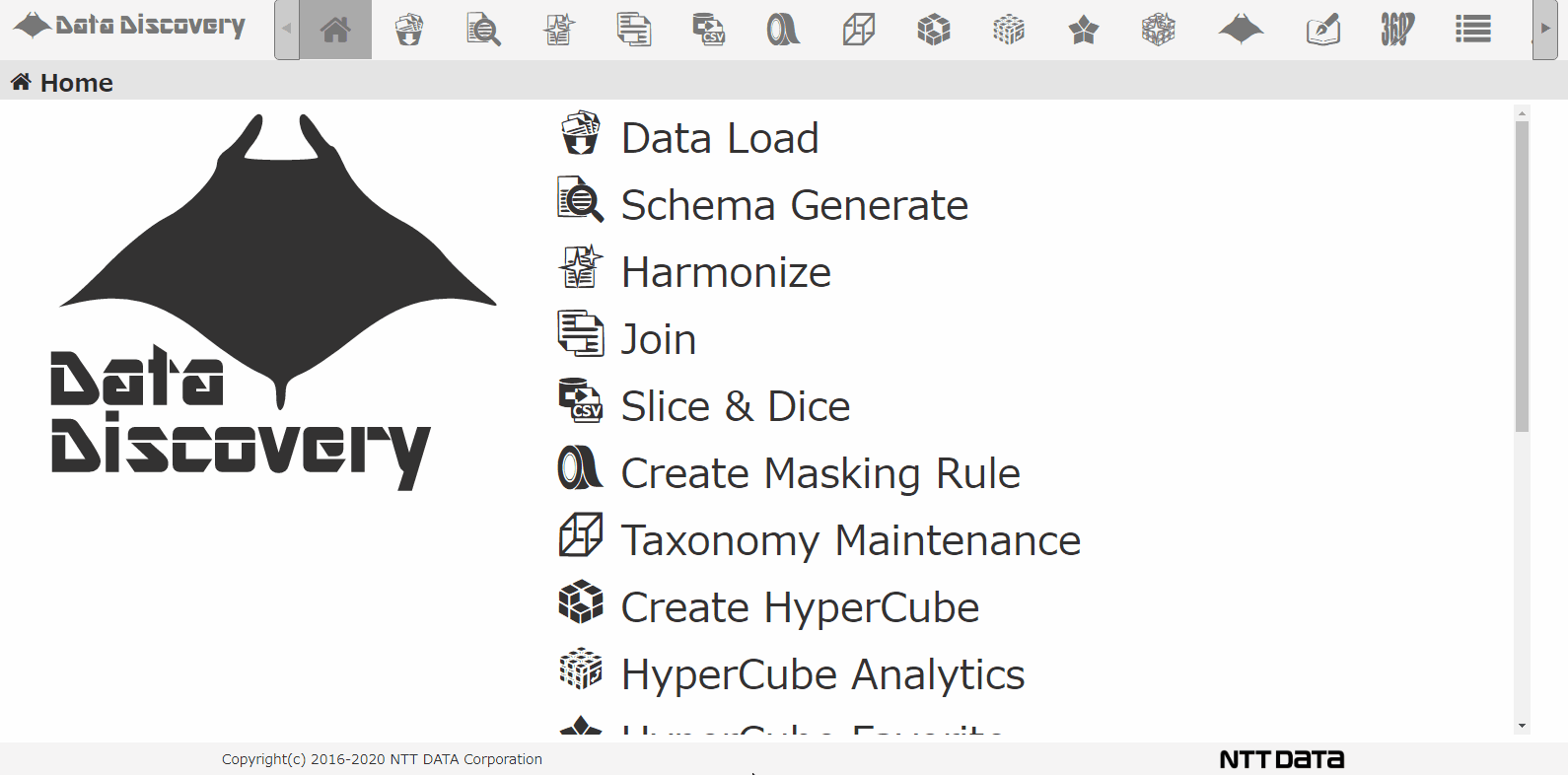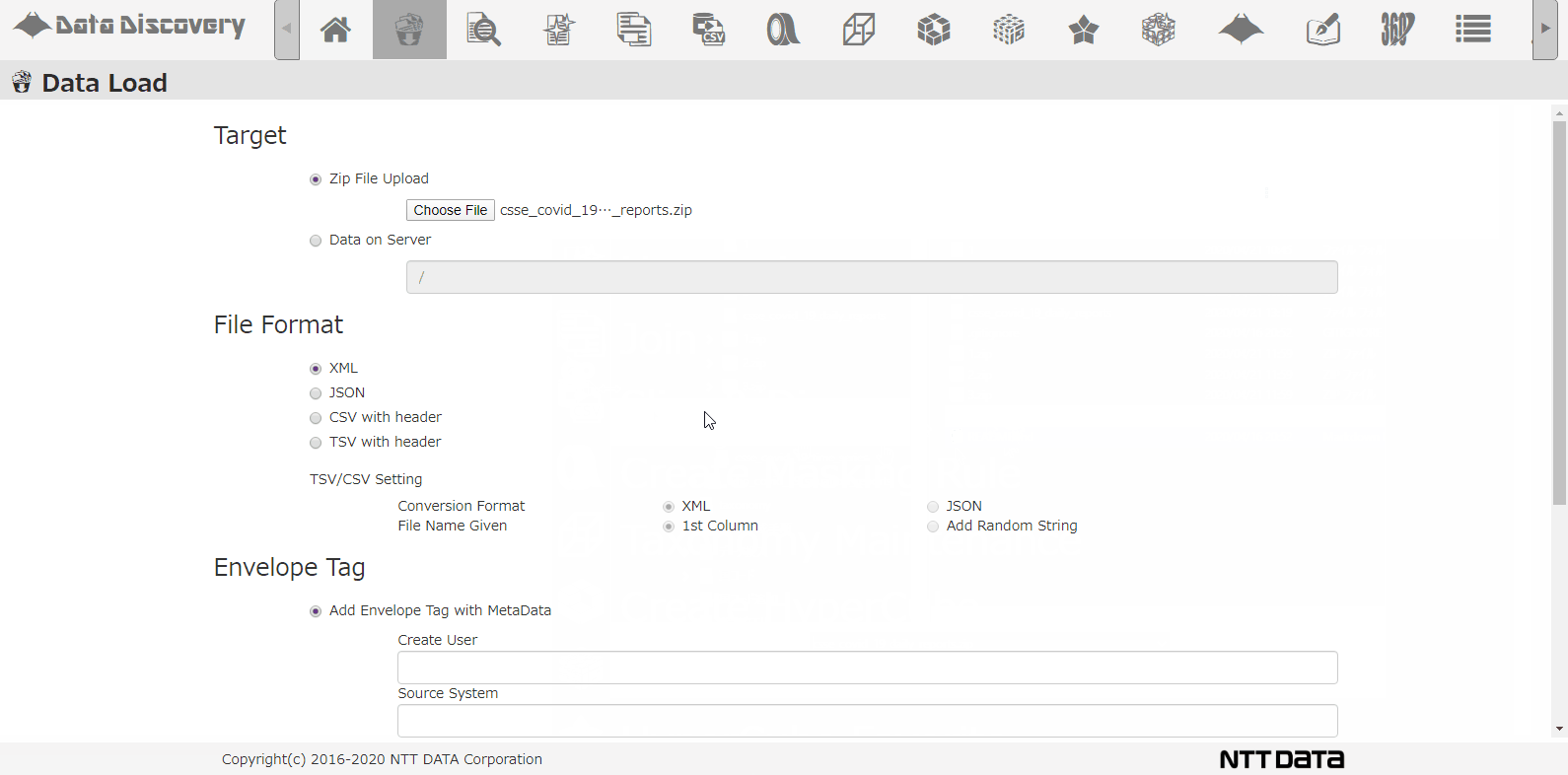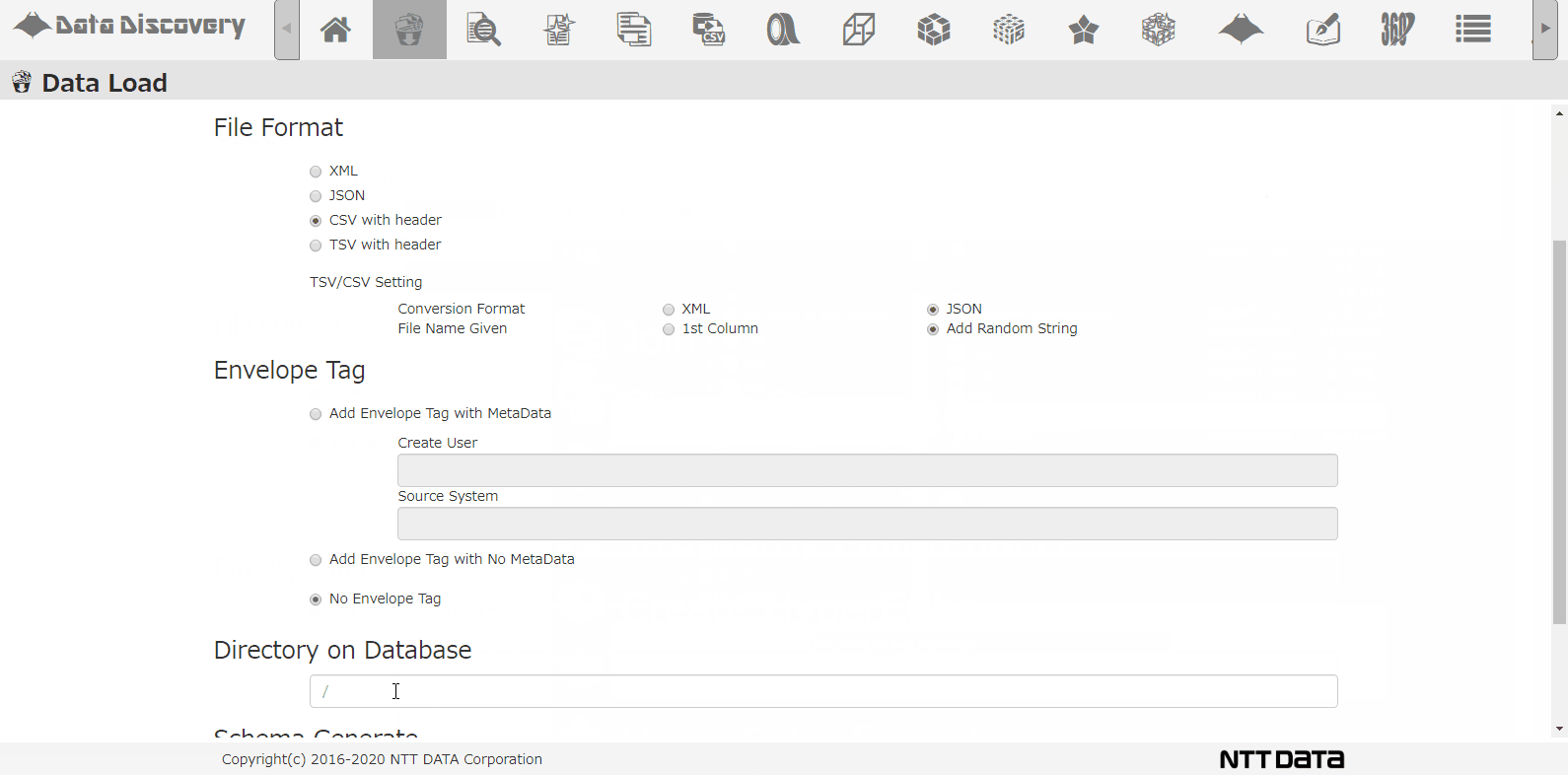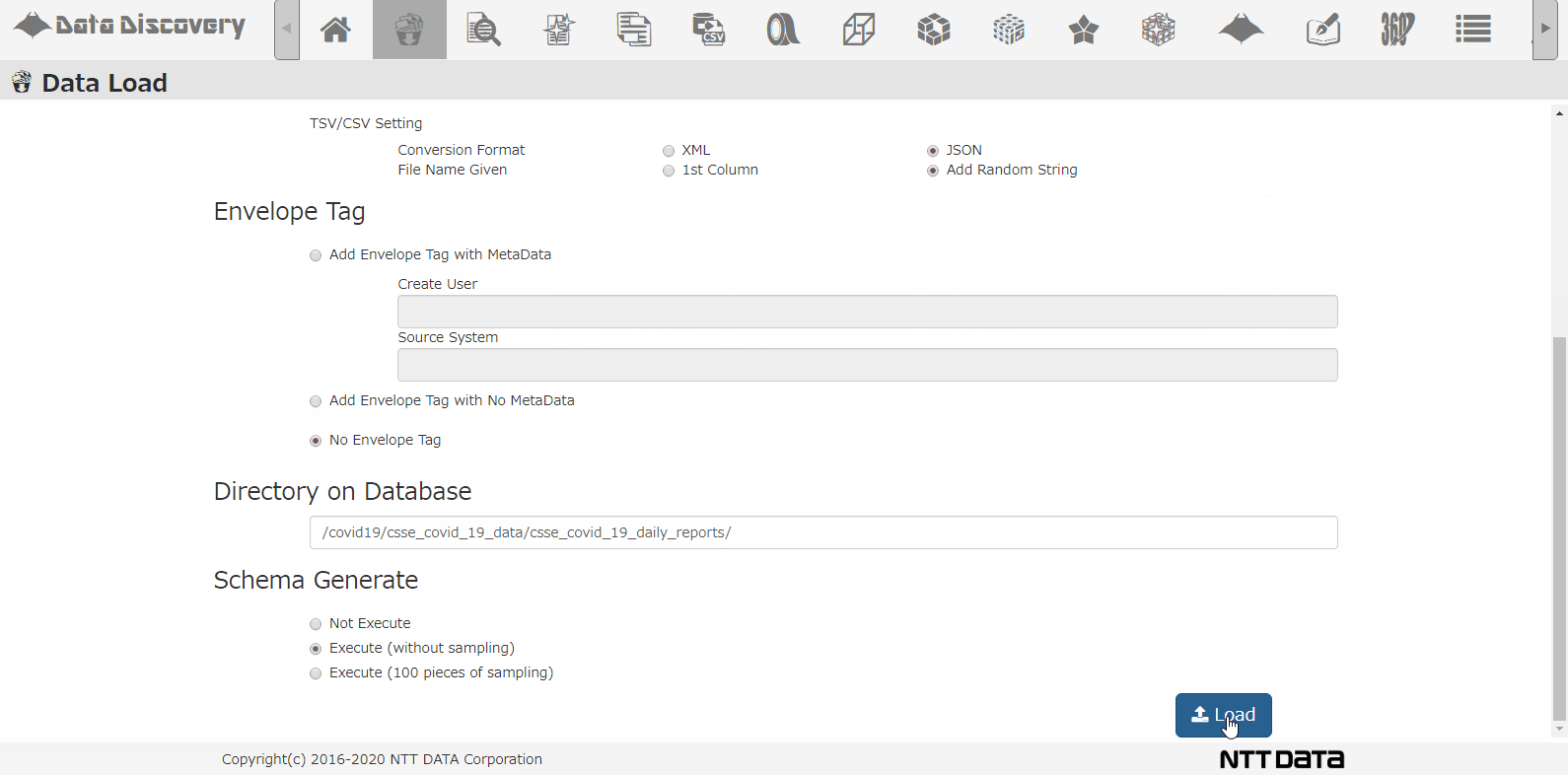
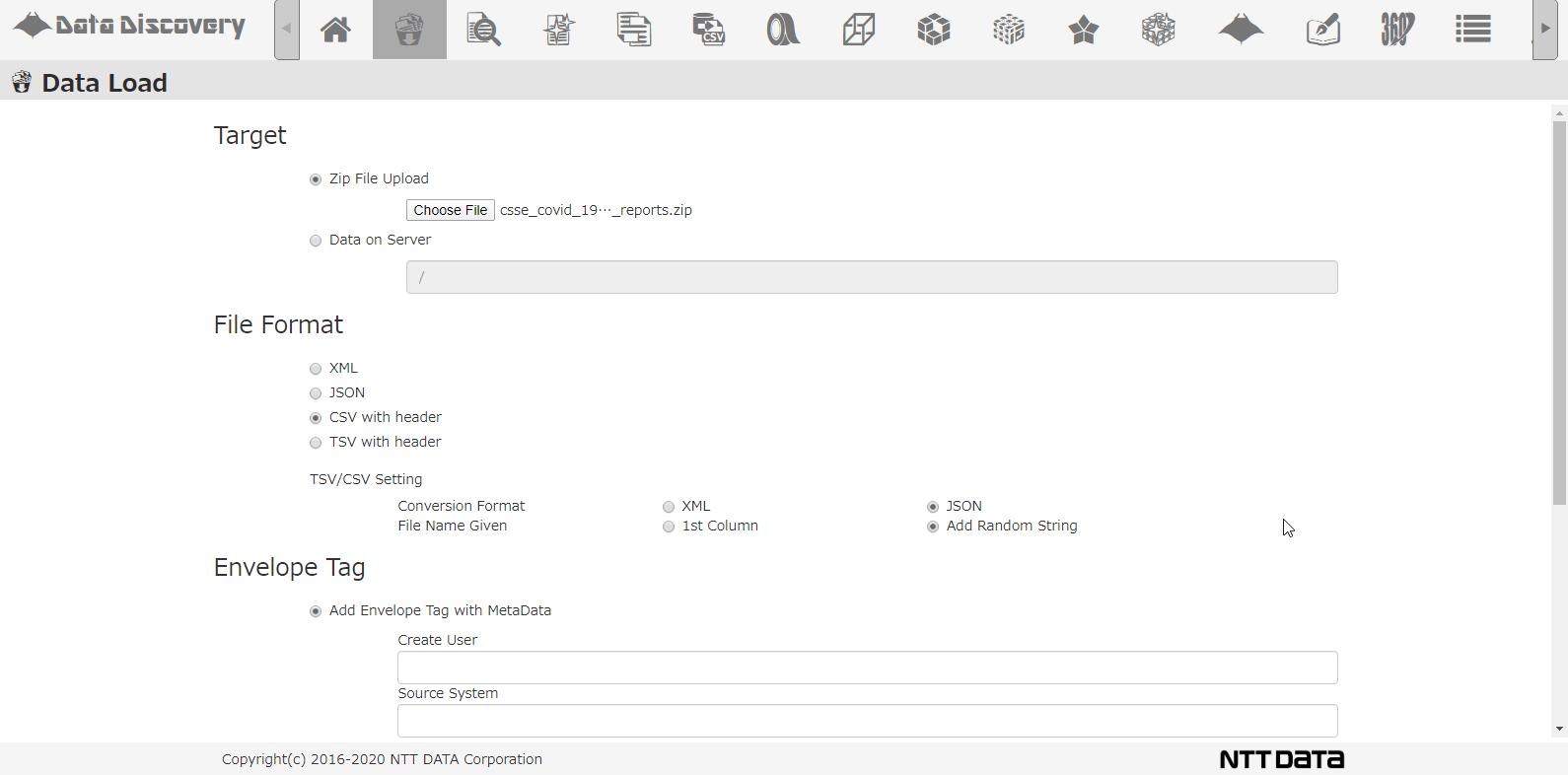
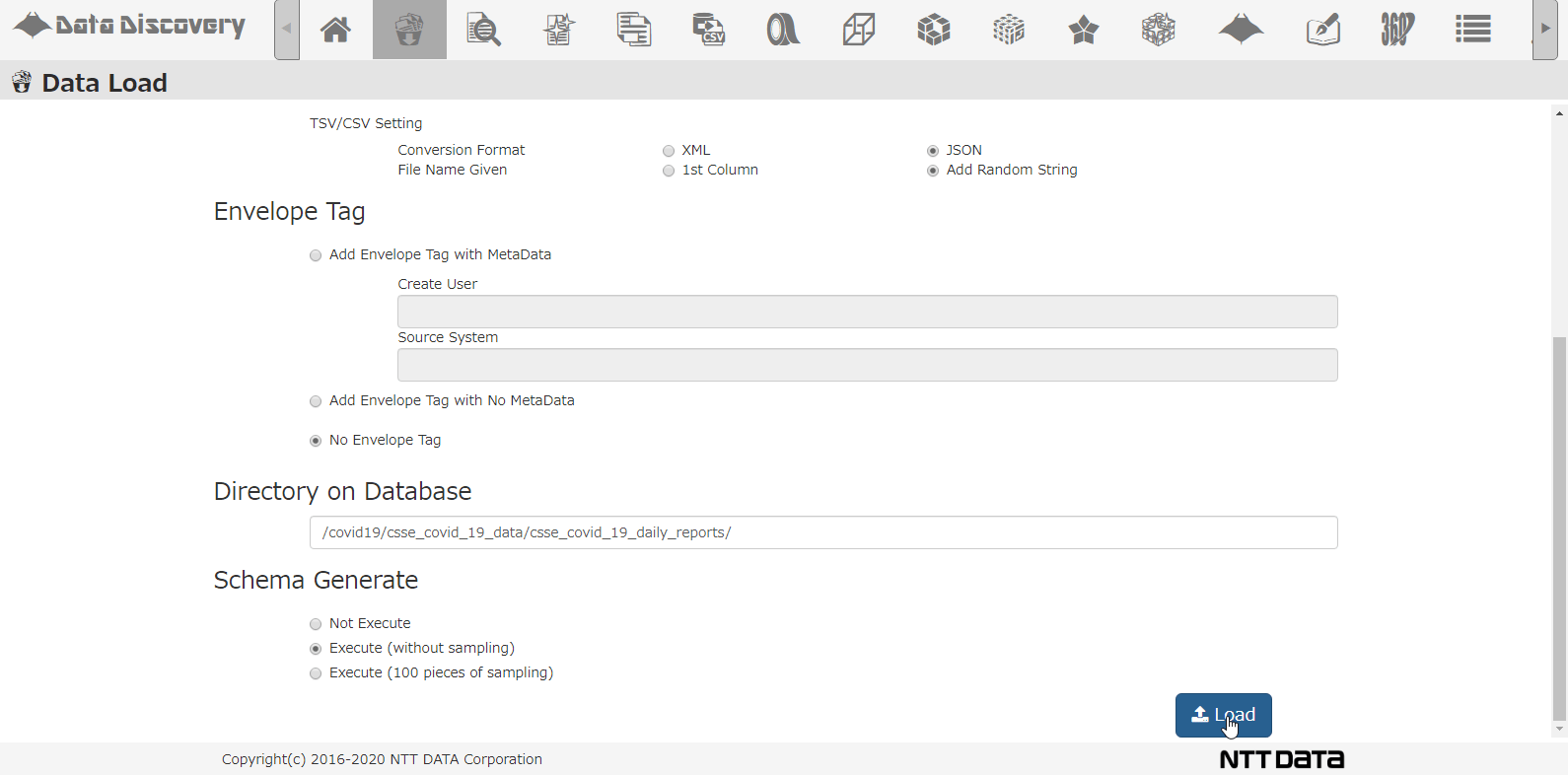
私たちのツール「DataDiscovery™」のデータロード機能を使って、複数のCSVを圧縮したZIPファイルを一括登録する様子は以下のアニメーションの通りです。
CSVロード画面です。ロード対象ファイルをダイアログから選択します。ロード対象ファイルのファイル形式としてCSVを選び、JSONに変換しながらDBに格納するようにします。
格納先のDBディレクトリを指定して、スキーマ解析するオプションを指定して、Loadボタンを押下します。
画面上の操作は、たったこれだけです。あとはバッチ処理でDBにデータを登録した後、実データを解析してどんなカラムが存在するのか調査してくれます。この一連のバッチ処理に掛かる時間は、データ量にもよりますが、今回は86日分のデータで10分弱でした。
RDBにこのデータを登録する場合、まず86個のファイルをすべて開いて、どんなカラムが存在するのか、そしてそれらがどんなデータ型なのか調査する必要があります。その上で、調査結果を元にCREATE TABLE文を作ってDB上にテーブル定義したうえで、データを登録する必要があります。NoSQLデータベースの場合、これらの手間が全く無くなっている(データベースやツールに任せることができる)ということがご理解いただけると思います。
なお、NoSQLデータベースにCSVデータを登録した場合、CSVの1行(1レコード)を1つのJSONファイルに変換して登録されます。
例えば、以下のようなCSVファイルのレコードの場合は、
以下のようなJSONファイルに変換されてDBに登録されます。
まとめ:スキーマレスDBはレイアウト変更に強い
GitHubからジョンズ・ホプキンス大学のデータをダウンロードするのに1分も掛からず、中身をざっと見て内容把握するのに10分。対象と決めたデータをNoSQLデータベースに登録し、スキーマ解析するのに10分。都合、ここまでに要した時間はわずか20分でした。
レイアウトが頻繁に変わるようなデータセットを扱う際に、スキーマレスDBがいかに有効か、ご理解いただけたかと思います。
次回は、登録したデータの中身を確認して、クレンジングしていきます。