(6) ジョンズ・ホプキンス大データをHyperCube化する
前回は、データセット横断で分析をする際の汎用的なデータモデル「HyperCube」について簡単にご説明しました。今回は、既にNoSQLデータベースに導入している「ジョンズ・ホプキンス大学が開示しているCOVID-19関連データ」を、実際にHyperCube化していきます。
手順1:データモデリング
HyperCube化する手順は、大きく「1.データモデリング」「2.実データの変換」という2つのステップに分かれます。まずは、「データモデリング」を実施していきます。
ConceptとDimensionの定義
HyperCubeのデータモデリングの第一歩は、FactデータがどのようなConceptとDimensionを持つか、定義することです。
ジョンズ・ホプキンス大学が開示しているCOVID-19関連データは、こんなデータでした。
- いつ時点(年月日)の
- どの国の
- どの州の(米国と中国のみ)
- どの郡の(米国のみ)
- 累積感染者数/累積死亡者数/累積回復者数/アクティブ感染者数は
- 何人だ
HyperCubeでいう「Concept」は「累積感染者数/累積死亡者数/累積回復者数/アクティブ感染者数」の4種類です。
Conceptに対応する「Value」は「何人」の部分です。
Dimensionは「時点」「国」「州」「郡」の4つです。
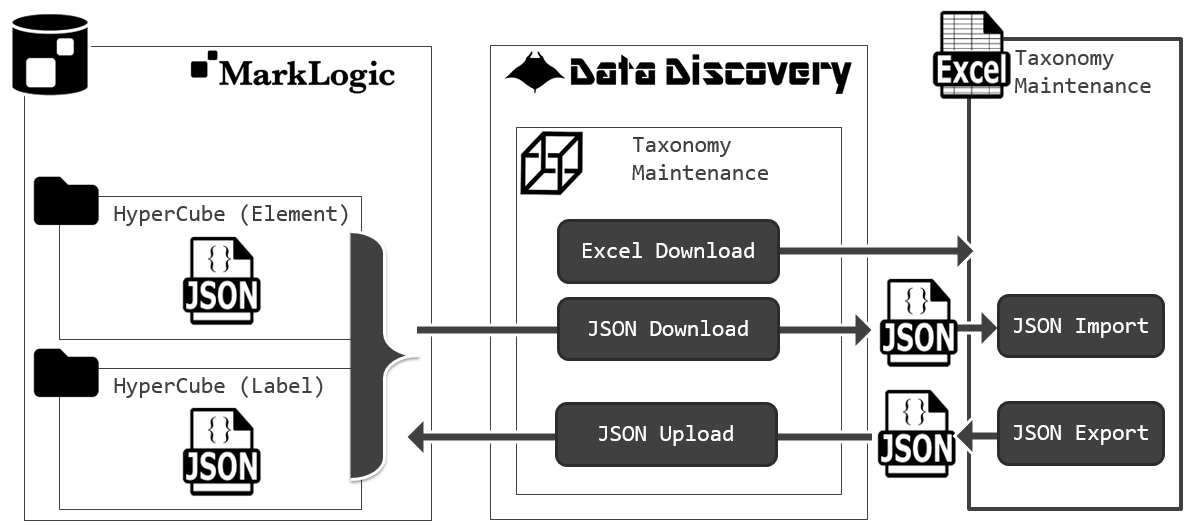
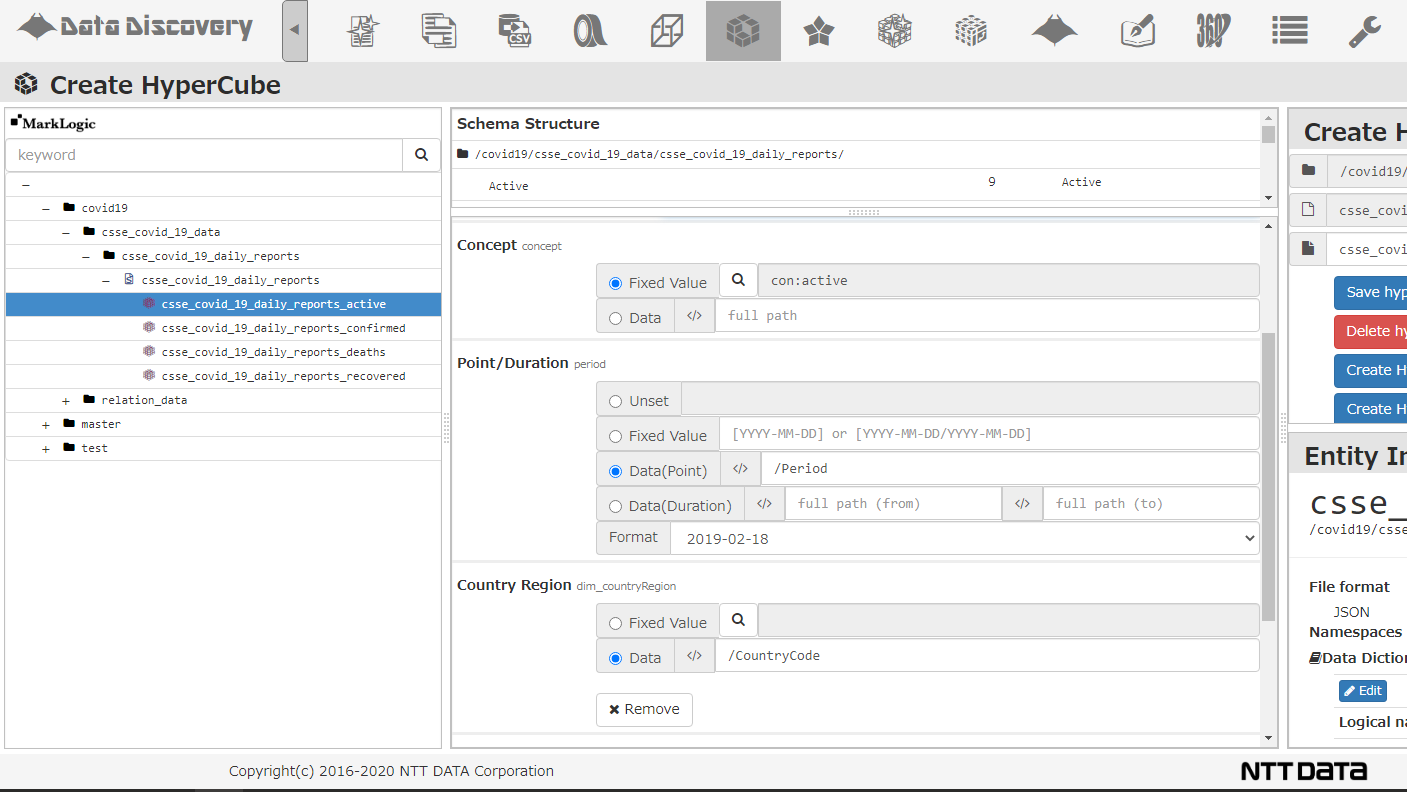
私たちのソリューション「DataDiscovery™」では、Taxonomy Maintenance画面を通じて専用のExcel様式をダウンロードし、Excel上でこれらのConceptやDimensionを定義します。そして、Excelから定義体を出力し、画面からシステムに登録することができます。
手順2:実データの変換
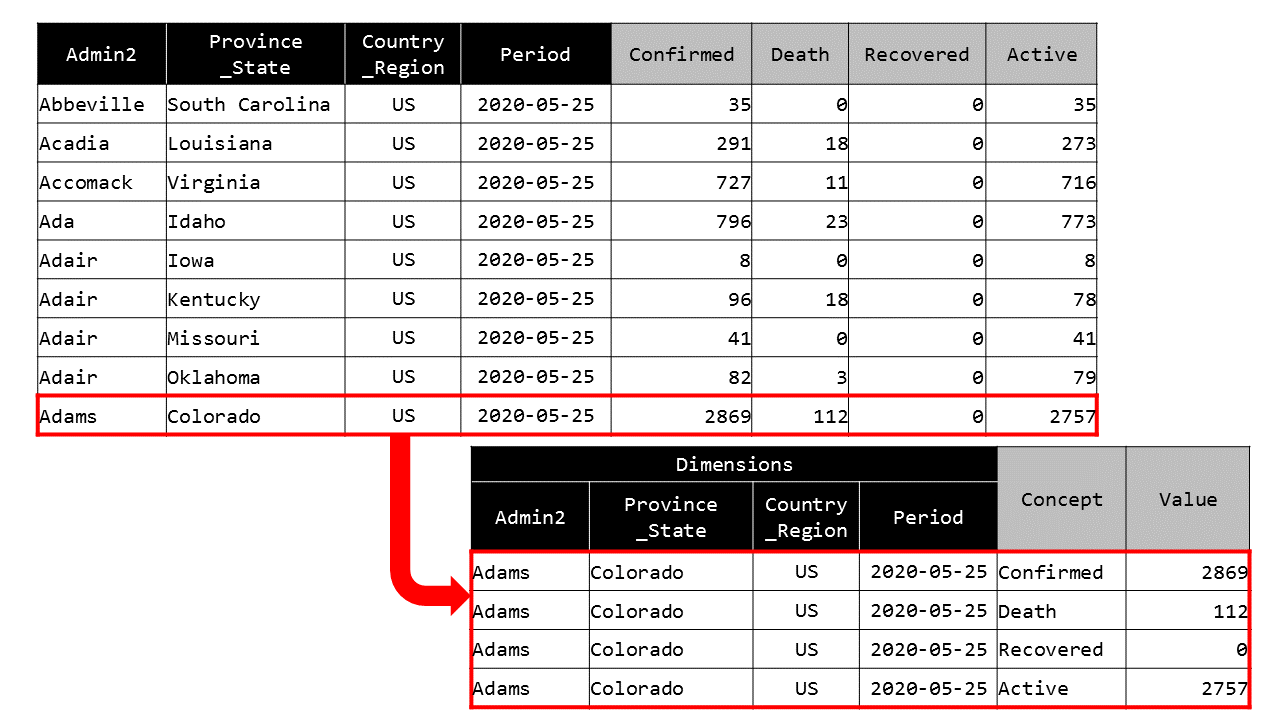
上記の様式定義に従って、実データを変換していきます。
以下のようにオリジナルデータ1行から4つのHyperCube Factデータが作られるイメージです(Conceptの種類が4つなので)。
これは、もちろんデータベース上のクエリで実行することもできますが、私たちのソリューション「DataDiscovery™」では、「Create HyperCube画面」からGUIベースで変換定義を作り、バッチ実行させることが可能です。
HyperCubeを使ったデータ分析
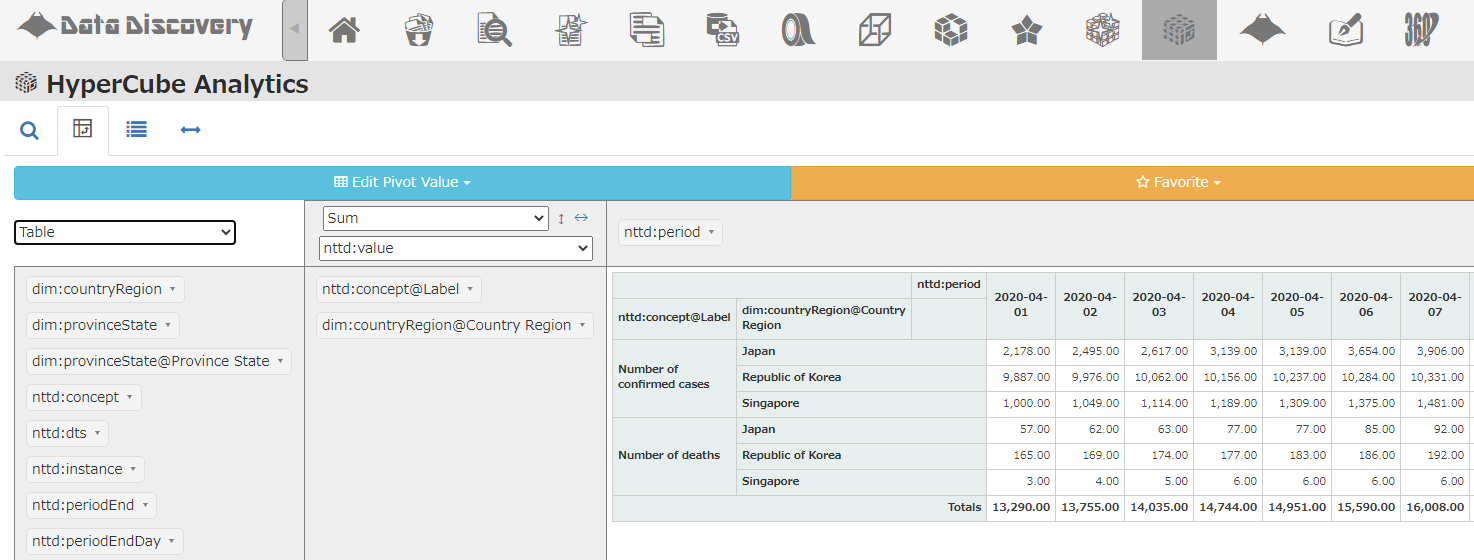
以上、ジョンズ・ホプキンス大学のデータをHyperCube化しました。これによって、私たちのDataDiscovery™ソリューションの「HyperCube Analytics」画面で、ブラウザ上でのPivot分析が可能になります。
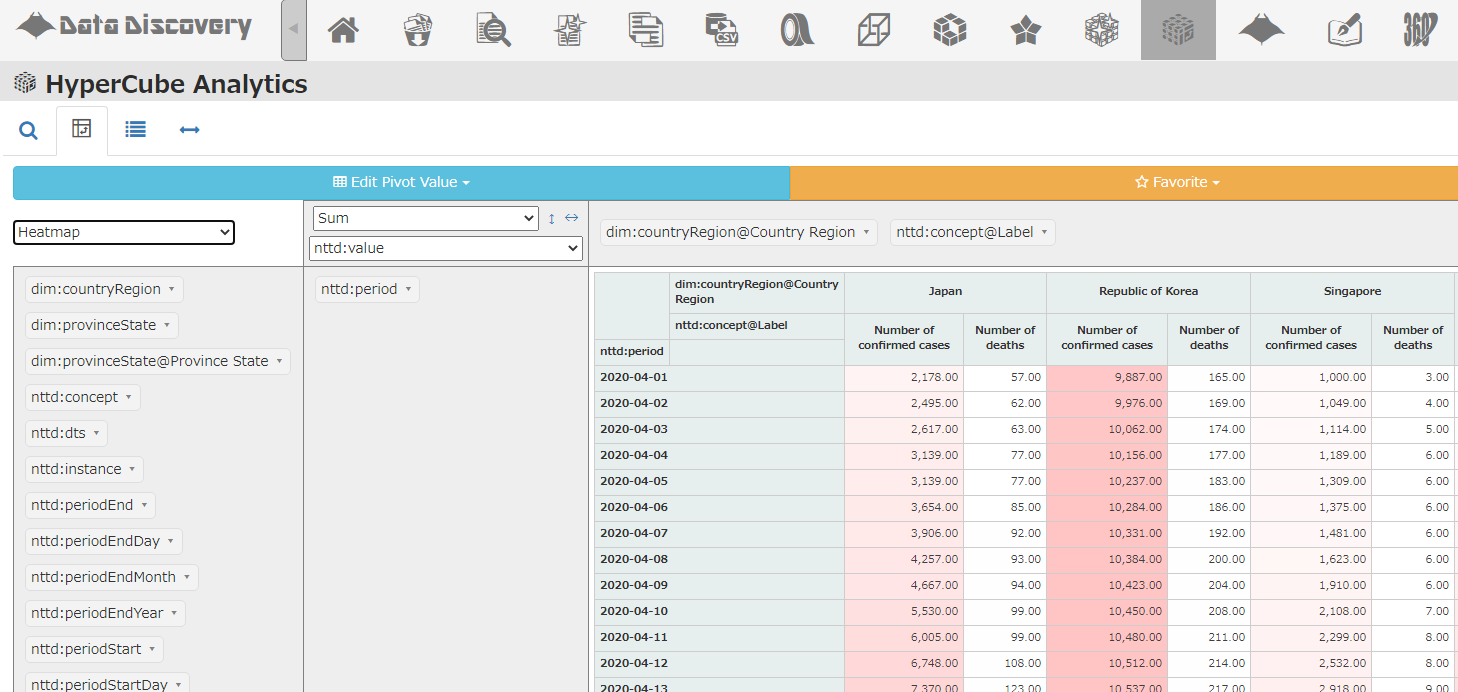
例えば、縦軸に「Concept(感染者数か死亡者数か)」「国」を設定し、横軸に「日付」を設定すると、以下のようなピボットテーブルが描画されます。
また、縦軸に「日付」、横軸に「国」と「Concept」を設定することで、以下のようなPivotを描画できます。このように、分析する人の目的に応じて、縦軸と横軸をあれこれ自在に入れ替えて分析することができるということです。
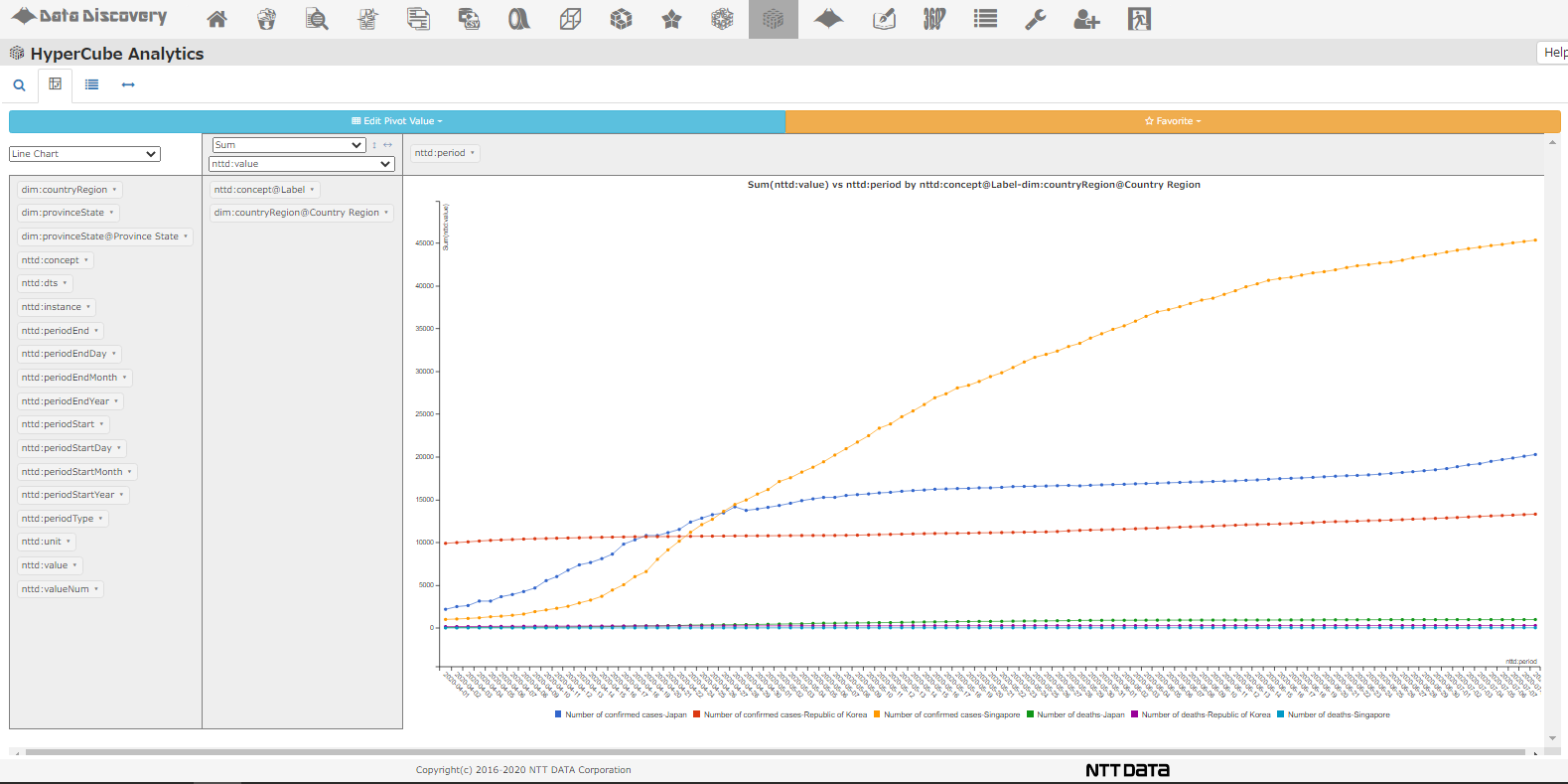
そして、日々の国別の感染者数と死亡者数を折れ線グラフに描画することもできます。
まとめ:HyperCubeで自在な分析が可能に
今回は、ジョンズ・ホプキンス大学のCOVIDデータを実際にHyperCube化し、それによってブラウザ上で「自在な」分析ができることを示しました。
しかし、読者の中にはこのように思う方もいるでしょう。「ブラウザでPivot分析ができることは分かった。しかし、それがHyperCube化と何の関係があるんだ? HyperCube化しなくてもPivot分析はできるはずだ」と。
そして、その考えは完全に正しいです。実は、HyperCubeの真の効果は「まったく由来の異なるデータセット同士を分析する場合」に発揮されます。次回は、ジョンズ・ホプキンス大学のデータに、まったく別のデータを掛け合わせることで、HyperCubeの効用を確認していきます。