(4) コード体系の標準化クレンジング
前回は、ジョンズ・ホプキンス大学が開示しているCOVID-19関連データのクレンジングの一環で、「途中で変更されたカラム名(JSONプロパティ名)」をNoSQLデータベース上で標準化しました。今回も引き続き、DBデータをクレンジングしていきます。
クレンジング2:日付フォーマットを標準化
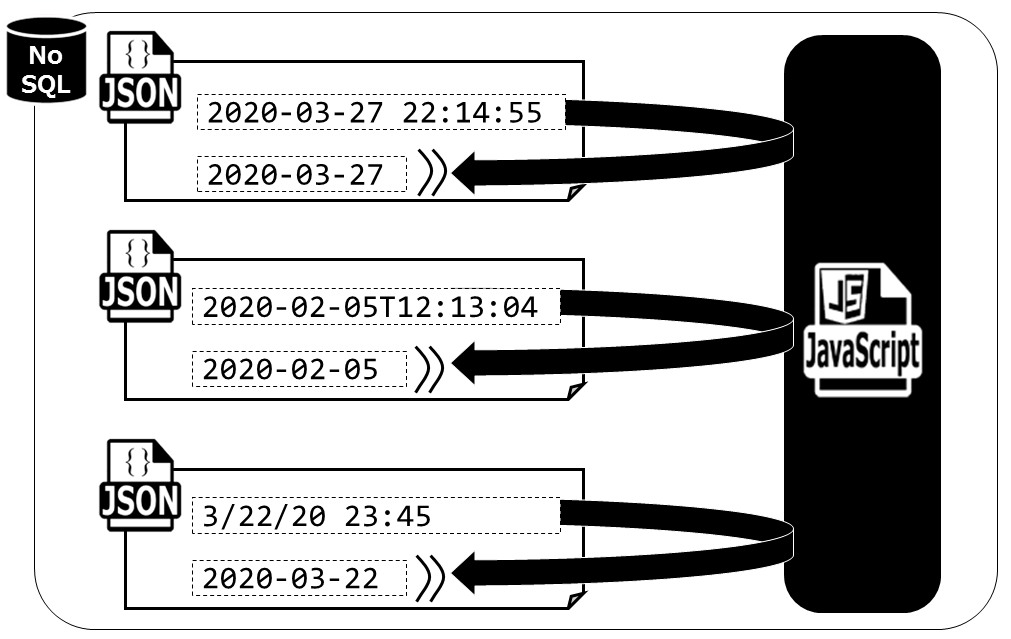
DBデータの実際の値をサンプリングしながら確認していくと、Last_Updateという項目の表記の揺らぎが気になりました。この項目は日付時刻型のデータなのですが、その文字列表現として以下の3種類が混在していることが分かったのです。
2020-03-27 22:14:552020-02-05T12:13:043/22/20 23:45
1つ目と2つ目はよく似ていますが、日付と時刻の間に「T」が含まれているかどうかで異なります。
このLast_Updateという項目は「各国の感染者数/死亡者数/回復者数」といったデータについて「いつ時点の」という分析軸を与えるもので、非常に重要です。表記が揺らいでいると困るのでこれをYYYY-MM-DD形式で標準化することにしました。Last_Updateの値を書き換えてもよいのですが、今回はLast_Updateの値は触らずそのままに、新たにPeriodというJSONプロパティを追加してみることにします。
例えば、加工前のDBデータは以下のようになっています。
これを、以下の通り、Periodを追加する形で加工しようというものです。
前回の連載同様、NoSQLデータベース内で以下の処理を実行することで、標準化された日付項目を追加しました。
クレンジング3:国と地域を標準化
続いて、「どの国の」感染者数/死亡者数/回復者数なのかを示すCountry_Regionという項目に着目し、どんな値が含まれているのか、DBデータを調べてみました。
これで取得した「国/地域」の値を見てみると、いくつか課題が見つかりました。
「国/地域」の表記の揺らぎを確認
まず、同じ国/地域なのに表記が異なる例です。
Russia と Russian FederationUnited Kingdom と UKCabo Verde と Cape VerdeViet Nam と VietnamGuernsey と Channel Islands
中国の特別行政区(Special Administrative Region)も、表記揺らぎが見られます。
Hong Kong と Hong Kong SARMacao と Macao SAR
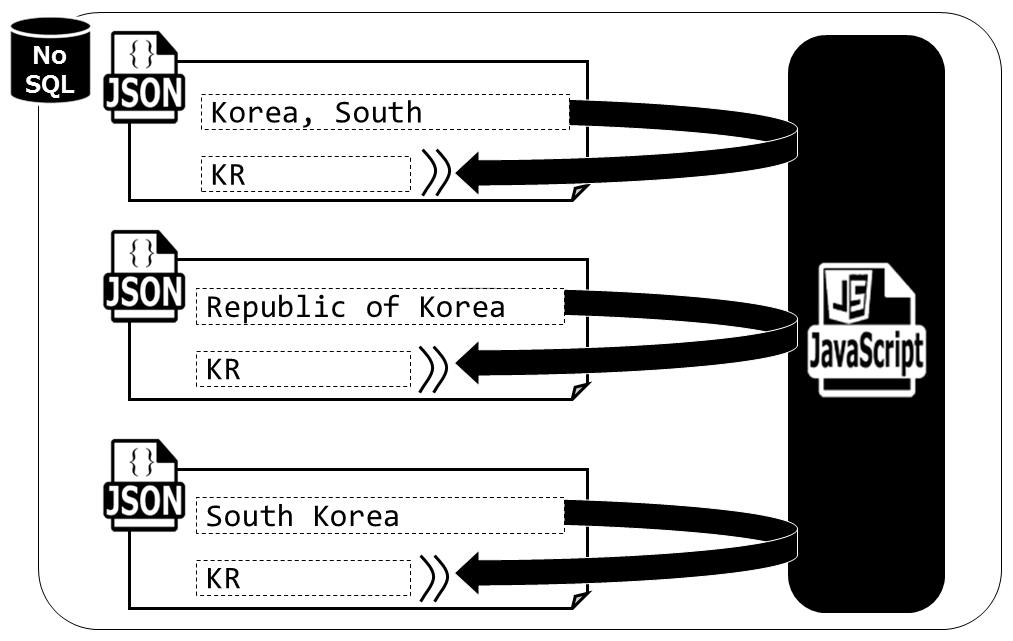
国名に「Republic」が付くか否かの揺らぎも多く見られました。
Ireland と Republic of IrelandCzechia と Czech RepublicMoldova と Republic of MoldovaIran と Iran (Islamic Republic of)Korea, South と Republic of Korea と South Korea
同様に、国名に「The」が付くか、どこに付くかでの揺らぎも見られます。
Bahamas と Bahamas, The と The BahamasGambia と Gambia, The と The Gambia
「国/地域名」欄に「クルーズ船の名前」が出てくるのも、このデータセットの大きな特徴でしょう
Cruise ShipDiamond PrincessMS Zaandam
どのような事情があったのか不明ですが、「その他」としか扱えない何らかの事情があったのだろうと思われる「国/地域名」もありました。
国/地域の標準コード体系を設定
ジョンズ・ホプキンス大学のデータの中でも表記が揺れていますし、今後 他のデータセットと組み合わせていくことも考えると、このタイミングでコード体系を正しく整えた方がよいと考えました。
国/地域のコードとしては、ISO3166-1のコード体系を利用することにしました。Country_Regionの値は変えることなく、新たにCountryCodeという項目を追加するようにしています。
上述の例だと、以下の通り末尾にCountryCodeという値が付与されるイメージです。
これは、NoSQLデータベース内で以下の処理を実行することで実現しました。
30~34行目に読替辞書を作っています(本稿では省略していますが、実際はずっと長いです)。これによってRussia も Russian Federationも等しくRUとして表現されるようになります。また、Diamond PrincessのようなISOの国コードに変換不能な値は、いったんそのままCountryCodeにしています。
まとめ:新たな項目(カラム)をどんどん追加していく
今回も、前回同様「DBに格納してから段階的にクレンジングしていく」という、スキーマレスDBの柔軟性が発揮される方法論を見てきました。
特に今回は、Period とかCountryCodeという新規の項目を段階的に追加している点に注目してください。これは、RDBでいうと、テーブルに対してどんどんカラムを追加していくイメージです。こういうことをシステム停止などせずに手軽にできるのは、スキーマレスなNoSQLデータベースの大きな特徴です。
また今回の「国/地域」の標準化は、ISOで定められた既存のコード体系を流用することで、手間を省くことができました。当然、他のデータセットとの結合しやすさも視野にいれています。
次回は、ここまでのデータを使っていよいよ「国別の感染者数等の時系列比較」の折れ線グラフを描画していきます。